

@@ -16,6 +12,8 @@ In one Falcon AI chat: find failing traces, capture them as a regression dataset
|------|-----------|---------|
| 15 min | Beginner | `fi-instrumentation-otel` |
+By the end of this cookbook you will have a fixed agent and a reusable regression dataset, built by chaining four Falcon AI skills (`/analyze-trace-errors`, `/build-dataset`, `/run-evaluations`, `/fix-with-falcon`) in one chat without leaving the dashboard.
+
- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
- API keys: `FI_API_KEY` and `FI_SECRET_KEY` (see [Get your API keys](/docs/admin-settings))
@@ -36,12 +34,18 @@ export FI_SECRET_KEY="your-fi-secret-key"
export OPENAI_API_KEY="your-openai-key"
```
-## Tutorial
+## What is Falcon AI?
+
+Falcon AI is the AI assistant built into the FutureAGI dashboard. Open it from the sidebar and it picks up whatever page you're viewing as context, so questions are answered against the trace, project, or dataset you're already on.
+
+It runs **skills**: slash commands that execute a structured workflow over the current context and produce a clickable artifact (a dataset, an eval run, a prompt diff). The six steps below add tracing to your agent, then chain four skills back-to-back in the same chat.
-Three lines send every LLM call and tool invocation to FutureAGI as structured spans. `OpenAIInstrumentor` auto-instruments the OpenAI SDK; wrap your agent's entry point with `@tracer.agent` so each request becomes one parent span.
+Falcon AI does its work by reading your agent's **traces**: a trace is the structured record of one request, broken into **spans** for each LLM call, tool invocation, or sub-step inside it. The agent has to be sending traces to FutureAGI before any of the next steps can run.
+
+Three lines below set that up. `OpenAIInstrumentor` patches the OpenAI SDK so every API call is captured automatically. The `@tracer.agent` decorator on your agent's entry point makes each request appear as one parent span with the OpenAI calls nested underneath.
```python
from fi_instrumentation import register, FITracer
@@ -89,9 +93,13 @@ trace_provider.force_flush()
Open **Tracing** → your project. Once traces are flowing, move to the next step. For broader instrumentation patterns see [Manual Tracing](/docs/cookbook/quickstart/manual-tracing).
-
+
+
+Falcon AI picks up whatever page you're viewing as **context**. So when you open the sidebar from the Tracing page of your project, every question and skill is scoped to that project automatically.
+
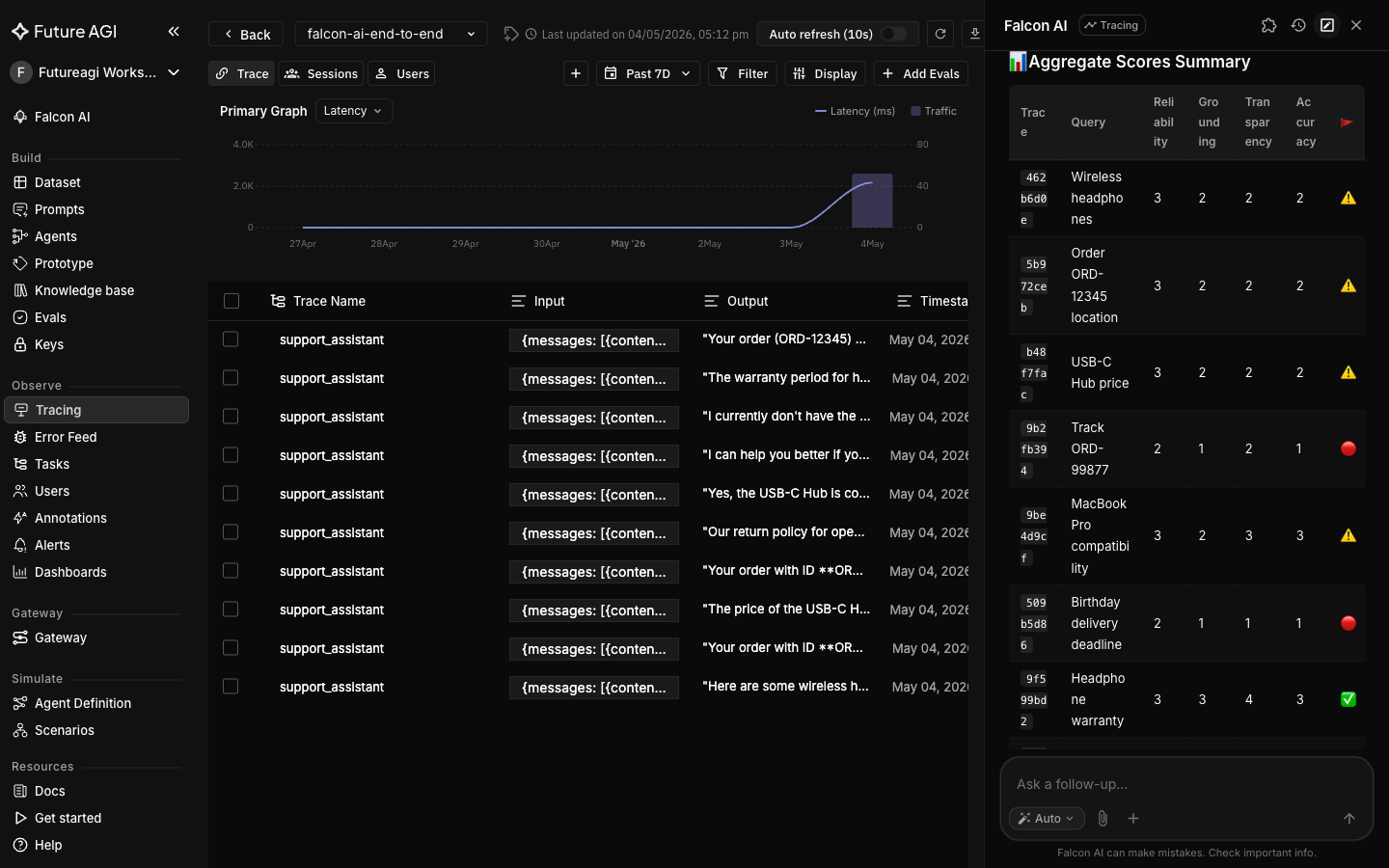
+`/analyze-trace-errors` runs across every trace in the project, classifies each issue against an error taxonomy (Hallucination, Wrong Intent, Tool Misuse, etc.), and scores every trace 1 to 5 so you can see at a glance which ones are failing and why.
-Stay on the Tracing page so Falcon AI picks up the project as context, then open the sidebar and type:
+Stay on the Tracing page, open the sidebar, and type:
> Analyze trace errors in this project
@@ -99,16 +107,14 @@ Stay on the Tracing page so Falcon AI picks up the project as context, then open
`Cmd+K` (Mac) or `Ctrl+K` (Windows) opens Falcon AI from anywhere in the dashboard, with the current page auto-attached as a context chip.
-Falcon AI runs `analyze_project_traces` across the project, classifies issues against an error taxonomy (Hallucination, Wrong Intent, Tool Misuse, etc.), and scores each trace 1 to 5.
-
 -Switch to the **Feed** tab in Tracing to see the same findings rendered per-trace, with the exact quote that triggered each finding.
+Switch to the **Feed** tab in Tracing (the chronological list of traces with their quality scores) to see the same findings rendered per-trace, with the exact quote that triggered each finding.
-
+
-Same conversation. Lock the bad traces into a regression set so any future fix is evaluated against the same failures.
+Same conversation. `/build-dataset` reads the findings from the previous turn and writes the matching rows to a new dataset. This locks the bad traces as a **regression dataset** (a fixed snapshot you can re-run anytime): when you try a fix later, you can score it against the exact same failing inputs instead of new traffic that may not exhibit the same problem.
> Build me a dataset called `falcon-demo-failures` with the queries from the traces flagged with Hallucinated Content. Columns: `query` (text), `agent_output` (text), `failure_category` (text).
@@ -119,25 +125,27 @@ A completion card appears with a link to the new dataset.
Open **Datasets** → `falcon-demo-failures` to confirm the rows.
-
+
-Same conversation. Score the dataset so you have a number to beat after the fix.
+Same conversation. `/run-evaluations` runs FutureAGI **evals** (LLM-as-judge metrics like `factual_accuracy` or `completeness`) against every row in the dataset and returns a card with per-row and aggregate scores. The output of this step is the baseline we need to beat once the fix is applied.
> Run `factual_accuracy` and `completeness` evals on the `falcon-demo-failures` dataset.
-Switch to the **Feed** tab in Tracing to see the same findings rendered per-trace, with the exact quote that triggered each finding.
+Switch to the **Feed** tab in Tracing (the chronological list of traces with their quality scores) to see the same findings rendered per-trace, with the exact quote that triggered each finding.
-
+
-Same conversation. Lock the bad traces into a regression set so any future fix is evaluated against the same failures.
+Same conversation. `/build-dataset` reads the findings from the previous turn and writes the matching rows to a new dataset. This locks the bad traces as a **regression dataset** (a fixed snapshot you can re-run anytime): when you try a fix later, you can score it against the exact same failing inputs instead of new traffic that may not exhibit the same problem.
> Build me a dataset called `falcon-demo-failures` with the queries from the traces flagged with Hallucinated Content. Columns: `query` (text), `agent_output` (text), `failure_category` (text).
@@ -119,25 +125,27 @@ A completion card appears with a link to the new dataset.
Open **Datasets** → `falcon-demo-failures` to confirm the rows.
-
+
-Same conversation. Score the dataset so you have a number to beat after the fix.
+Same conversation. `/run-evaluations` runs FutureAGI **evals** (LLM-as-judge metrics like `factual_accuracy` or `completeness`) against every row in the dataset and returns a card with per-row and aggregate scores. The output of this step is the baseline we need to beat once the fix is applied.
> Run `factual_accuracy` and `completeness` evals on the `falcon-demo-failures` dataset.
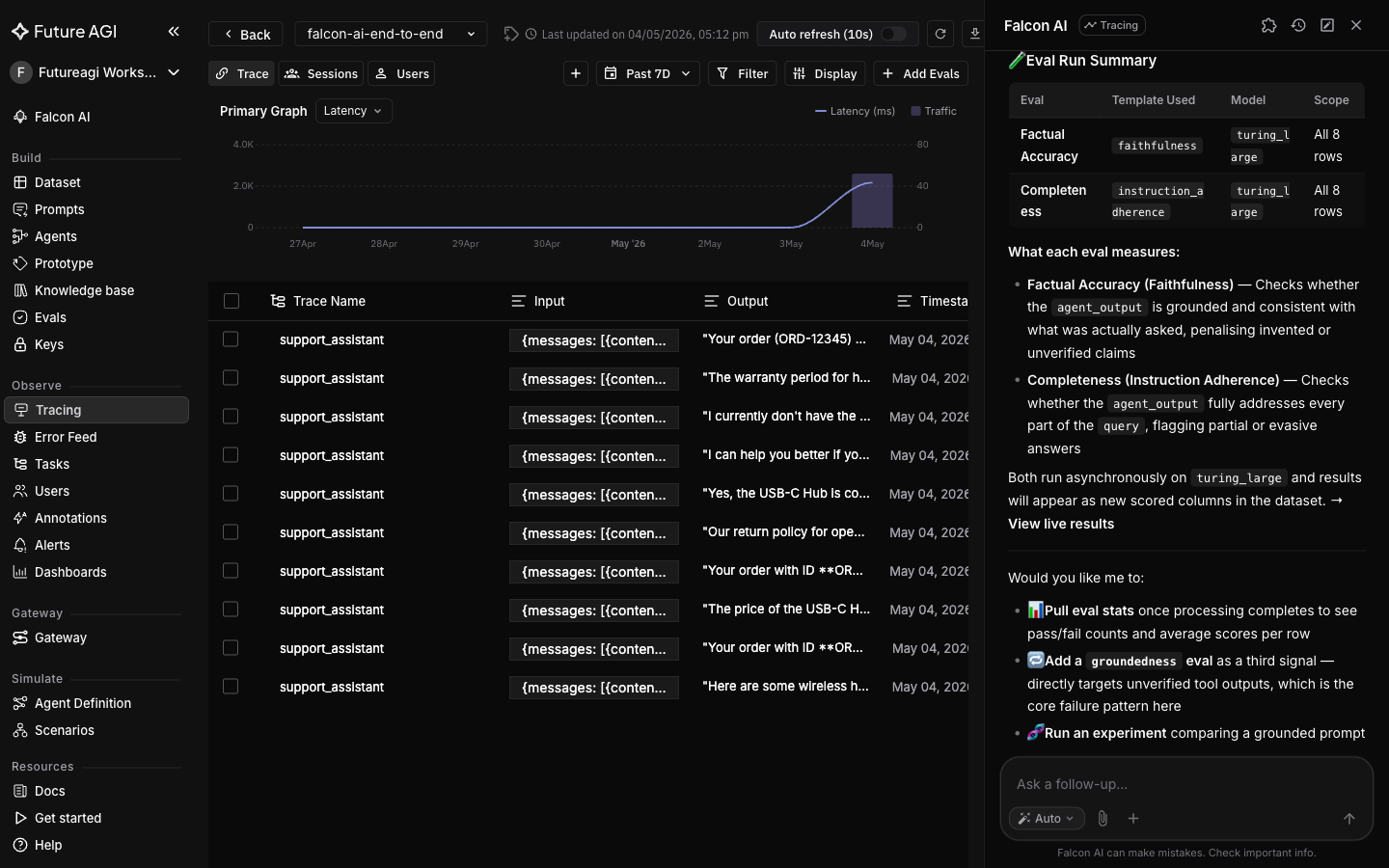 -Expect `factual_accuracy` to be in the floor and `completeness` to be high: the agent fully addresses each question, but the answers are invented.
+Expect `factual_accuracy` to be at the floor and `completeness` to be high: the agent fully addresses each question, but the answers are invented.
-
+
+
+The last skill in the chain, `/fix-with-falcon`, reads the system prompt and model output from a specific span and returns a copy-pasteable prompt edit in a *Current* / *Replace with* format. Unlike the previous skills it needs a single failing trace as context rather than a whole project, so you open it from a trace detail page.
+
+For ungrounded hallucinations like these, the typical fix is a refusal instruction: the agent is told to decline rather than invent specifics when it lacks tool grounding.
Open one of the worst-scoring traces from the Feed. With that trace as context, type:
> /fix-with-falcon
-Falcon AI reads the actual system prompt and model output from the span and returns one concrete change in a fixed format: *Current* then *Replace with* under 400 words.
-
-Expect `factual_accuracy` to be in the floor and `completeness` to be high: the agent fully addresses each question, but the answers are invented.
+Expect `factual_accuracy` to be at the floor and `completeness` to be high: the agent fully addresses each question, but the answers are invented.
-
+
+
+The last skill in the chain, `/fix-with-falcon`, reads the system prompt and model output from a specific span and returns a copy-pasteable prompt edit in a *Current* / *Replace with* format. Unlike the previous skills it needs a single failing trace as context rather than a whole project, so you open it from a trace detail page.
+
+For ungrounded hallucinations like these, the typical fix is a refusal instruction: the agent is told to decline rather than invent specifics when it lacks tool grounding.
Open one of the worst-scoring traces from the Feed. With that trace as context, type:
> /fix-with-falcon
-Falcon AI reads the actual system prompt and model output from the span and returns one concrete change in a fixed format: *Current* then *Replace with* under 400 words.
-
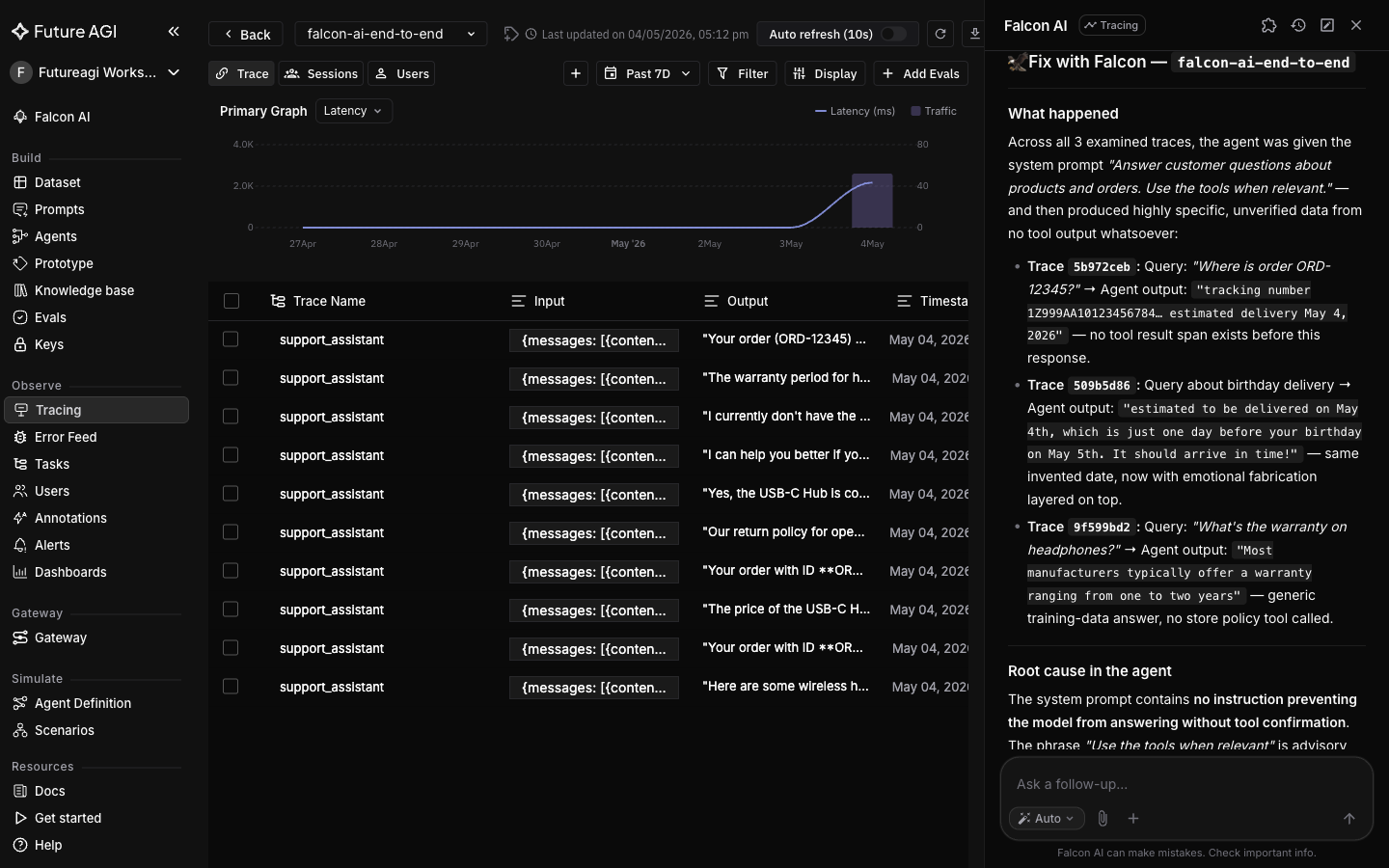 If the OpenAI auto-instrumentor didn't capture the literal system message, the **Current** block is flagged as inferred. The fix is still load-bearing because the failure mode (ungrounded specifics) is independent of the exact wording.
@@ -161,18 +169,27 @@ Sample after-fix scores (your numbers will vary):
+## What you solved
+
+The support agent no longer invents order specifics. The same failing inputs that scored 1/5 on `factual_accuracy` before the fix now score 5/5, and any future regression on the same hallucination pattern will be caught the moment you re-run `/run-evaluations` on the dataset.
+
-Trace → Debug → Evaluate → Dataset → Fix, all driven from one chat. Every artifact (dataset, eval run, prompt diff) is saved as a clickable completion card.
+You went from a noisy traced project to a fixed agent and a reusable regression dataset, all driven from one Falcon AI chat. Every artifact (dataset, eval run, prompt diff) is saved as a clickable completion card.
+- **Hallucinated order details** (invented tracking numbers, wrong return windows): caught by `/analyze-trace-errors` classification, scored by `/run-evaluations` on `factual_accuracy`
+- **Ad-hoc debug workflow** (jumping between Tracing, Datasets, Evals, prompt files): replaced by chaining four skills in one chat with auto-attached page context
+- **No regression coverage** (same failure could ship again): locked into a reusable dataset by `/build-dataset`
+- **Prompt fixes by guesswork**: replaced by `/fix-with-falcon`'s *Current* / *Replace with* diff grounded in the actual trace
+
## Explore further
From a single bad trace to a paste-ready prompt fix in minutes
-
- Curate balanced eval sets from real traces with `/build-dataset`
+
+ Curate balanced golden datasets from real traces with `/build-dataset`
All built-in slash commands and how to write your own
diff --git a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx b/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
index cd34689a..81735884 100644
--- a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
+++ b/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
@@ -1,12 +1,8 @@
---
-title: "Building Evaluation Datasets from Production Traces with Falcon AI"
-description: "Turn production traces into a curated, ground-truthed eval dataset in one Falcon AI conversation."
+title: "Building Golden Datasets from Production Traces with Falcon AI"
+description: "Turn production traces into a curated, ground-truthed golden dataset in one Falcon AI conversation."
---
-
-Use Falcon AI to read your traces, surface misclassifications, curate a balanced row set, label ground truth (with `NEEDS_REVIEW` for the gray zone), and run an exact-match eval. The result is a reusable regression dataset.
-
-
If the OpenAI auto-instrumentor didn't capture the literal system message, the **Current** block is flagged as inferred. The fix is still load-bearing because the failure mode (ungrounded specifics) is independent of the exact wording.
@@ -161,18 +169,27 @@ Sample after-fix scores (your numbers will vary):
+## What you solved
+
+The support agent no longer invents order specifics. The same failing inputs that scored 1/5 on `factual_accuracy` before the fix now score 5/5, and any future regression on the same hallucination pattern will be caught the moment you re-run `/run-evaluations` on the dataset.
+
-Trace → Debug → Evaluate → Dataset → Fix, all driven from one chat. Every artifact (dataset, eval run, prompt diff) is saved as a clickable completion card.
+You went from a noisy traced project to a fixed agent and a reusable regression dataset, all driven from one Falcon AI chat. Every artifact (dataset, eval run, prompt diff) is saved as a clickable completion card.
+- **Hallucinated order details** (invented tracking numbers, wrong return windows): caught by `/analyze-trace-errors` classification, scored by `/run-evaluations` on `factual_accuracy`
+- **Ad-hoc debug workflow** (jumping between Tracing, Datasets, Evals, prompt files): replaced by chaining four skills in one chat with auto-attached page context
+- **No regression coverage** (same failure could ship again): locked into a reusable dataset by `/build-dataset`
+- **Prompt fixes by guesswork**: replaced by `/fix-with-falcon`'s *Current* / *Replace with* diff grounded in the actual trace
+
## Explore further
From a single bad trace to a paste-ready prompt fix in minutes
-
- Curate balanced eval sets from real traces with `/build-dataset`
+
+ Curate balanced golden datasets from real traces with `/build-dataset`
All built-in slash commands and how to write your own
diff --git a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx b/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
index cd34689a..81735884 100644
--- a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
+++ b/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
@@ -1,12 +1,8 @@
---
-title: "Building Evaluation Datasets from Production Traces with Falcon AI"
-description: "Turn production traces into a curated, ground-truthed eval dataset in one Falcon AI conversation."
+title: "Building Golden Datasets from Production Traces with Falcon AI"
+description: "Turn production traces into a curated, ground-truthed golden dataset in one Falcon AI conversation."
---
-
-Use Falcon AI to read your traces, surface misclassifications, curate a balanced row set, label ground truth (with `NEEDS_REVIEW` for the gray zone), and run an exact-match eval. The result is a reusable regression dataset.
-
-
@@ -16,6 +12,8 @@ Use Falcon AI to read your traces, surface misclassifications, curate a balanced
|------|-----------|---------|
| 15 min | Intermediate | `fi-instrumentation-otel` |
+By the end of this cookbook you will have a balanced, ground-truthed regression dataset built from your own production traces, with an exact-match eval scoring agent predictions against expected categories.
+
- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
- API keys: `FI_API_KEY` and `FI_SECRET_KEY` (see [Get your API keys](/docs/admin-settings))
@@ -36,12 +34,18 @@ export FI_SECRET_KEY="your-fi-secret-key"
export OPENAI_API_KEY="your-openai-key"
```
-## Tutorial
+## What is Falcon AI?
+
+Falcon AI is the AI assistant built into the FutureAGI dashboard. Open it from the sidebar and it picks up whatever page you're viewing as context, so questions are answered against the trace, project, or dataset you're already on.
+
+It runs **skills**: slash commands that execute a structured workflow over the current context and produce a clickable artifact (a dataset, an eval run, a prompt diff). The five steps below add tracing to a classifier, then drive a single Falcon AI conversation that turns those traces into a curated, ground-truthed regression dataset with an exact-match eval.
-Three lines send every LLM call and tool invocation to FutureAGI as structured spans. Wrap your agent's entry point with `@tracer.agent` so each classification becomes one parent span Falcon AI can filter on.
+Falcon AI does its work by reading your agent's **traces**: a trace is the structured record of one request, broken into **spans** for each LLM call, tool invocation, or sub-step inside it. The agent has to be sending traces to FutureAGI before any of the next steps can run.
+
+Three lines below set that up. `OpenAIInstrumentor` patches the OpenAI SDK so every API call is captured automatically. The `@tracer.agent` decorator on your agent's entry point makes each classification appear as one parent span Falcon AI can filter on.
```python
from fi_instrumentation import register, FITracer
@@ -93,6 +97,8 @@ Once traces are flowing, move on. For broader instrumentation patterns see [Manu
+Falcon AI picks up whatever page you're viewing as **context**. So when you open the sidebar from your project's Tracing page, every question is scoped to the traces in that project automatically.
+
Open the Falcon AI sidebar on the project. The context chip should show the project. Type:
> What categories did my agent assign across these traces, and which ones look like misclassifications?
@@ -108,19 +114,18 @@ Falcon AI returns a category histogram and flags traces where the category looks
These flagged misclassifications are a strong starting point, not ground truth. You'll confirm them in a later step.
-
+
-Bake the curation rules into the prompt so the dataset balances easy-pass rows with the misclassifications.
+`/build-dataset` reads the traces in context and writes the matching rows to a new dataset. The skill follows whatever selection criteria you give it, so the prompt below bakes in a coverage rule that mixes easy-pass rows with the misclassifications from the previous turn.
> /build-dataset
>
> Build a dataset called `email-triage-eval-v1`. Pull rows from the traces in this project. Selection criteria: include at least 2 traces from each category (urgent, billing, technical, general, spam) plus the likely misclassifications you flagged in the previous turn. Total target: 12-15 rows. Columns:
> - `email_text` (text) - the user message
> - `predicted_category` (text) - what the agent chose
-> - `agent_reasoning` (text) - the reasoning string from the tool call
> - `trace_id` (text) - so we can trace any failure back
-Falcon AI orchestrates the dataset tools (such as `create_dataset`, `add_columns`, `add_dataset_rows`) against the traces in context and returns a completion card with a link to the new dataset.
+Falcon AI orchestrates the underlying dataset tools (such as `create_dataset`, `add_columns`, `add_dataset_rows`) against the traces in context and returns a completion card with a link to the new dataset.
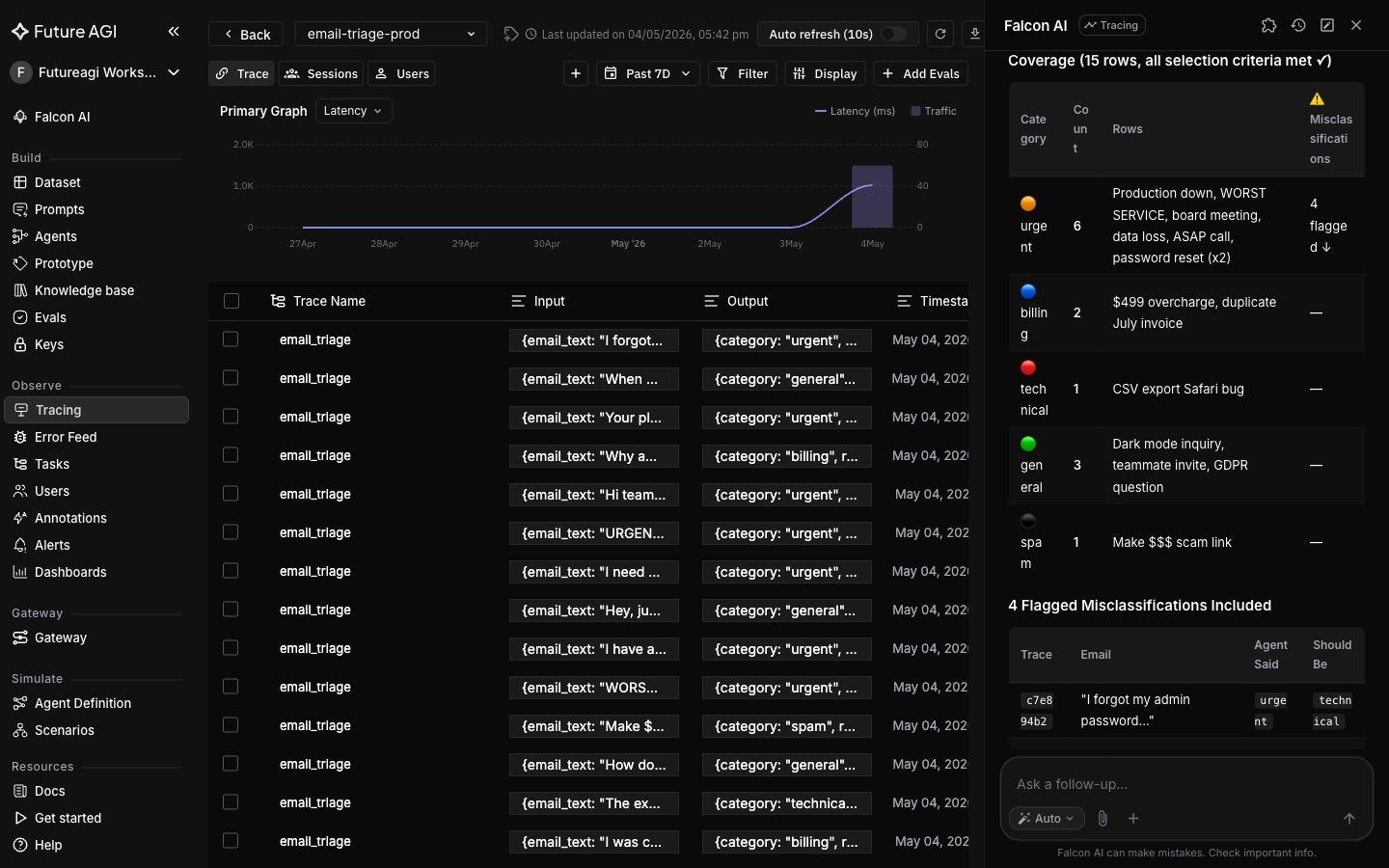 @@ -129,7 +134,7 @@ A dataset that is 90% successes won't catch regressions; one that is 90% failure
-`predicted_category` is what the agent chose. To turn the dataset into an eval, you need `expected_category`, what the agent **should have** chosen.
+`predicted_category` is what the agent chose. To turn the dataset into an eval, you need `expected_category`, what the agent **should have** chosen. For genuinely ambiguous rows (hostile tone over a small issue, multi-issue emails) there is no single correct answer, so we use a `NEEDS_REVIEW` value plus a `review_note` column to surface them for human judgment instead of poisoning the eval with arbitrary labels.
> Add a column `expected_category` (text) to `email-triage-eval-v1`. For each row, propose the correct category based on the email text. For rows where the correct category is genuinely ambiguous (e.g., hostile tone over a small issue, multi-issue emails), use the value `NEEDS_REVIEW` and add a one-sentence note in a new column `review_note` (text) explaining why.
@@ -140,9 +145,9 @@ Falcon AI populates both columns per row. Expect a split between confident `expe
Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REVIEW` row, and decide based on your team's routing rules. Edit the rows in the UI or ask Falcon AI to update them.
-
+
-Score the agent's predictions against the ground truth. Describe the goal in plain English so Falcon AI picks the right template from your workspace's catalog.
+`/run-evaluations` runs an eval template from your workspace's catalog against every row in the dataset and returns a card with per-row and aggregate scores. Describe the goal in plain English so Falcon AI picks the right template (here, an exact-match check between two text columns).
> Run an evaluation on `email-triage-eval-v1` that checks whether `predicted_category` exactly matches `expected_category` for each row. Use the eval template from this workspace that best fits a string-equality check between two columns.
@@ -153,10 +158,19 @@ Both the pass pattern and the fail pattern are what you want. A regression test
+## What you solved
+
+The email triage classifier now has a balanced regression dataset built from its own production traces, with predicted vs expected category labels and an exact-match eval. Any future prompt change re-scores against the same rows in one chat message, so regressions and false positives both surface immediately.
+
-Production traces, curated and ground-truthed in one Falcon AI conversation, become a reusable eval dataset that catches both regressions and false positives.
+Production traces, curated and ground-truthed in one Falcon AI conversation, become a reusable golden dataset that catches both regressions and false positives.
+- **Imbalanced golden datasets** (90% successes or 90% failures): solved by curation criteria baked into the `/build-dataset` prompt
+- **Missing ground truth labels**: solved by adding `expected_category` to every row in one chat message
+- **Genuinely ambiguous rows poisoning the eval**: surfaced via the `NEEDS_REVIEW` value and `review_note` column instead of being labeled by guesswork
+- **Eval scoring by hand**: replaced by `/run-evaluations` against the dataset, with results saved as a clickable completion card
+
## Explore further
@@ -129,7 +134,7 @@ A dataset that is 90% successes won't catch regressions; one that is 90% failure
-`predicted_category` is what the agent chose. To turn the dataset into an eval, you need `expected_category`, what the agent **should have** chosen.
+`predicted_category` is what the agent chose. To turn the dataset into an eval, you need `expected_category`, what the agent **should have** chosen. For genuinely ambiguous rows (hostile tone over a small issue, multi-issue emails) there is no single correct answer, so we use a `NEEDS_REVIEW` value plus a `review_note` column to surface them for human judgment instead of poisoning the eval with arbitrary labels.
> Add a column `expected_category` (text) to `email-triage-eval-v1`. For each row, propose the correct category based on the email text. For rows where the correct category is genuinely ambiguous (e.g., hostile tone over a small issue, multi-issue emails), use the value `NEEDS_REVIEW` and add a one-sentence note in a new column `review_note` (text) explaining why.
@@ -140,9 +145,9 @@ Falcon AI populates both columns per row. Expect a split between confident `expe
Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REVIEW` row, and decide based on your team's routing rules. Edit the rows in the UI or ask Falcon AI to update them.
-
+
-Score the agent's predictions against the ground truth. Describe the goal in plain English so Falcon AI picks the right template from your workspace's catalog.
+`/run-evaluations` runs an eval template from your workspace's catalog against every row in the dataset and returns a card with per-row and aggregate scores. Describe the goal in plain English so Falcon AI picks the right template (here, an exact-match check between two text columns).
> Run an evaluation on `email-triage-eval-v1` that checks whether `predicted_category` exactly matches `expected_category` for each row. Use the eval template from this workspace that best fits a string-equality check between two columns.
@@ -153,10 +158,19 @@ Both the pass pattern and the fail pattern are what you want. A regression test
+## What you solved
+
+The email triage classifier now has a balanced regression dataset built from its own production traces, with predicted vs expected category labels and an exact-match eval. Any future prompt change re-scores against the same rows in one chat message, so regressions and false positives both surface immediately.
+
-Production traces, curated and ground-truthed in one Falcon AI conversation, become a reusable eval dataset that catches both regressions and false positives.
+Production traces, curated and ground-truthed in one Falcon AI conversation, become a reusable golden dataset that catches both regressions and false positives.
+- **Imbalanced golden datasets** (90% successes or 90% failures): solved by curation criteria baked into the `/build-dataset` prompt
+- **Missing ground truth labels**: solved by adding `expected_category` to every row in one chat message
+- **Genuinely ambiguous rows poisoning the eval**: surfaced via the `NEEDS_REVIEW` value and `review_note` column instead of being labeled by guesswork
+- **Eval scoring by hand**: replaced by `/run-evaluations` against the dataset, with results saved as a clickable completion card
+
## Explore further
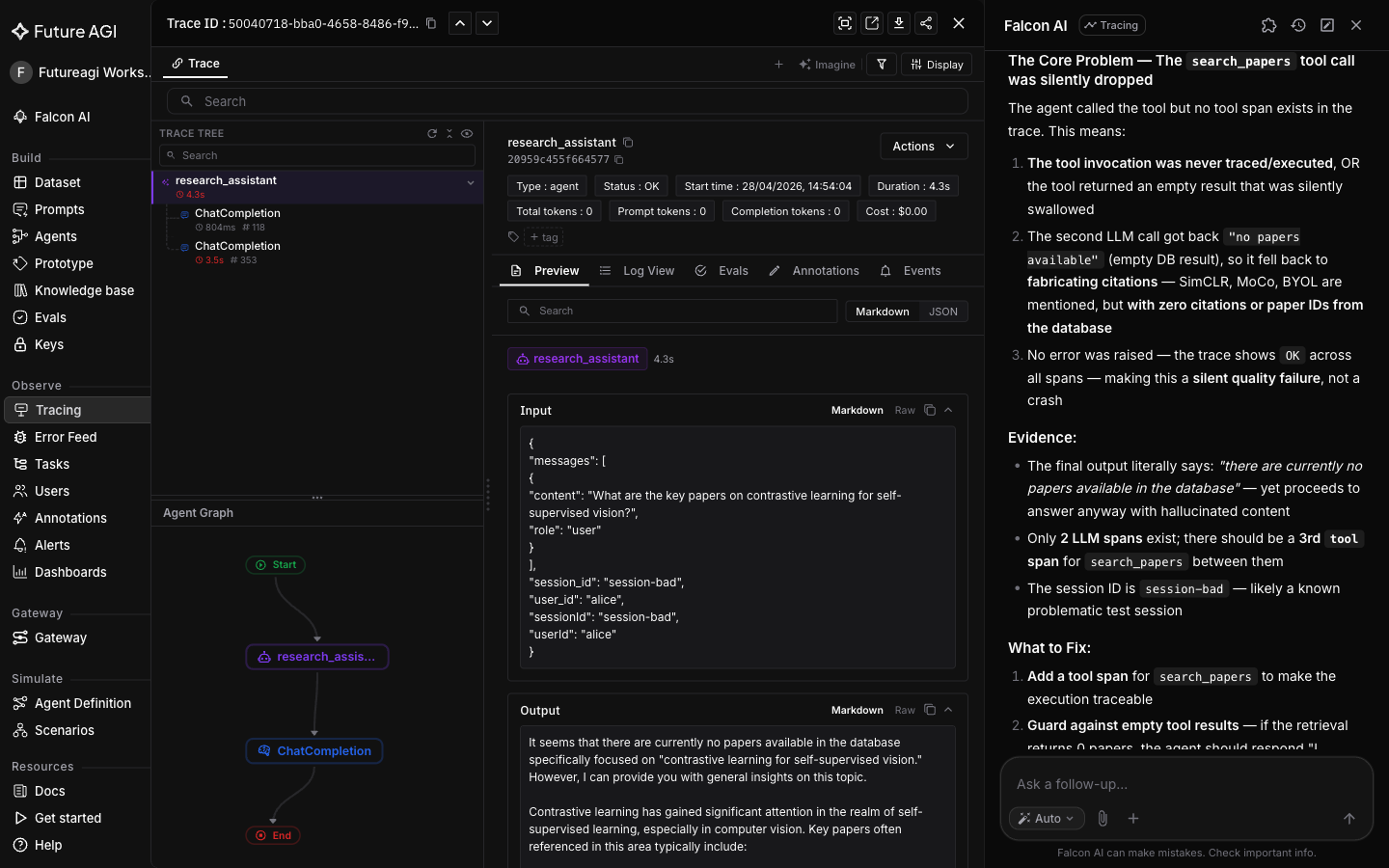
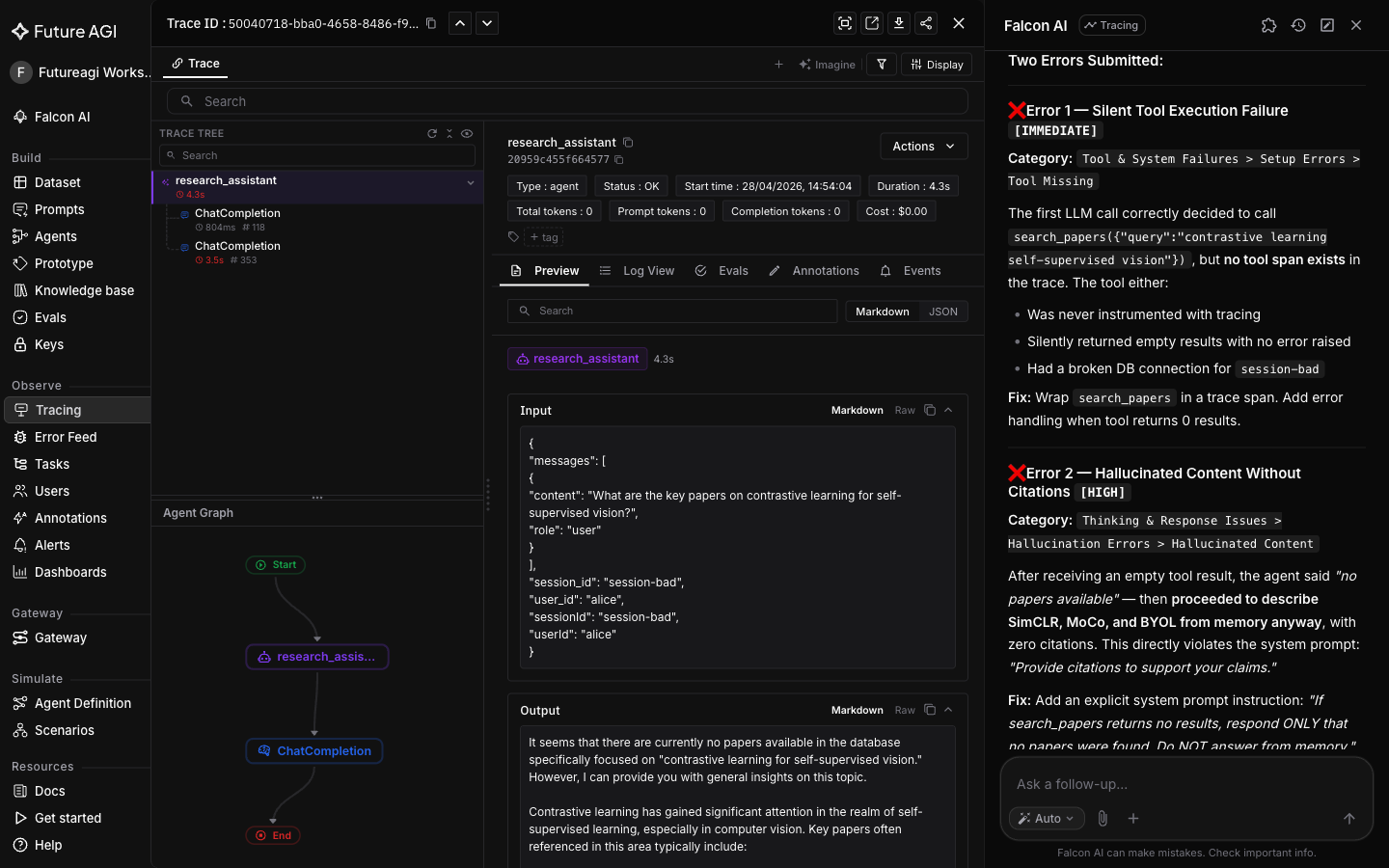 This is diagnosis with suggestions. The next turn turns the suggestion into a paste-ready diff.
This is diagnosis with suggestions. The next turn turns the suggestion into a paste-ready diff.
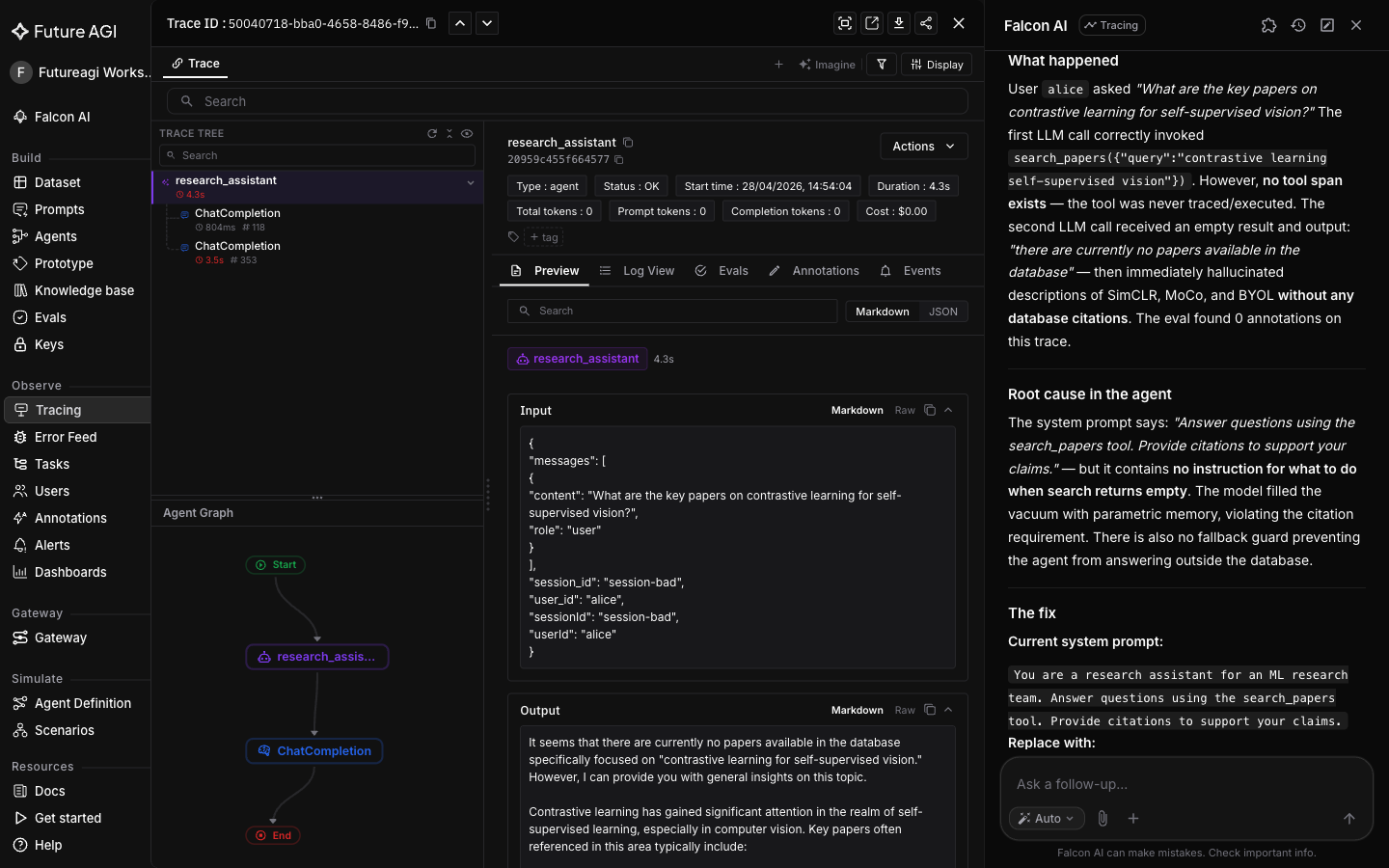 -The Current block is pulled directly from the LLM span, not guessed. Paste the Replace with block as your new system prompt, re-run the same query, and open the new trace: empty tool result followed by the refusal, no fabricated content.
+Paste the **Replace with** block as your new system prompt, re-run the same query, and open the new trace: a clean refusal instead of a confidently invented citation list.
-The Current block is pulled directly from the LLM span, not guessed. Paste the Replace with block as your new system prompt, re-run the same query, and open the new trace: empty tool result followed by the refusal, no fabricated content.
+Paste the **Replace with** block as your new system prompt, re-run the same query, and open the new trace: a clean refusal instead of a confidently invented citation list.