diff --git a/src/lib/navigation.ts b/src/lib/navigation.ts
index f8c26b39..969e5be4 100644
--- a/src/lib/navigation.ts
+++ b/src/lib/navigation.ts
@@ -824,7 +824,7 @@ export const tabNavigation: NavTab[] = [
items: [
{ title: 'End-to-End with Falcon AI: Trace → Debug → Evaluate → Dataset → Fix in One Workflow', href: '/docs/cookbook/falcon-ai/end-to-end' },
{ title: 'Context-Aware Trace Debugging with Falcon AI', href: '/docs/cookbook/falcon-ai/context-aware-debugging' },
- { title: 'Building Golden Datasets from Production Traces with Falcon AI', href: '/docs/cookbook/falcon-ai/eval-datasets-from-traces' },
+ { title: 'Building Golden Datasets from Production Traces with Falcon AI', href: '/docs/cookbook/falcon-ai/golden-datasets-from-traces' },
]
},
{
diff --git a/src/pages/docs/cookbook/falcon-ai/context-aware-debugging.mdx b/src/pages/docs/cookbook/falcon-ai/context-aware-debugging.mdx
index d35947b2..23a2eddb 100644
--- a/src/pages/docs/cookbook/falcon-ai/context-aware-debugging.mdx
+++ b/src/pages/docs/cookbook/falcon-ai/context-aware-debugging.mdx
@@ -157,7 +157,7 @@ You went from a failing trace to a verified prompt fix in three Falcon AI turns.
The full lifecycle: trace, debug, evaluate, dataset, fix in one workflow
-
+
Once you've fixed one trace, lock the failure pattern in as a regression dataset
diff --git a/src/pages/docs/cookbook/falcon-ai/end-to-end.mdx b/src/pages/docs/cookbook/falcon-ai/end-to-end.mdx
index 1530db76..62367093 100644
--- a/src/pages/docs/cookbook/falcon-ai/end-to-end.mdx
+++ b/src/pages/docs/cookbook/falcon-ai/end-to-end.mdx
@@ -188,7 +188,7 @@ You went from a noisy traced project to a fixed agent and a reusable regression
From a single bad trace to a paste-ready prompt fix in minutes
-
+
Curate balanced golden datasets from real traces with `/build-dataset`
diff --git a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx b/src/pages/docs/cookbook/falcon-ai/golden-datasets-from-traces.mdx
similarity index 85%
rename from src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
rename to src/pages/docs/cookbook/falcon-ai/golden-datasets-from-traces.mdx
index 81735884..e491a47f 100644
--- a/src/pages/docs/cookbook/falcon-ai/eval-datasets-from-traces.mdx
+++ b/src/pages/docs/cookbook/falcon-ai/golden-datasets-from-traces.mdx
@@ -4,8 +4,8 @@ description: "Turn production traces into a curated, ground-truthed golden datas
---
| Time | Difficulty | Package |
@@ -109,7 +109,7 @@ Open the Falcon AI sidebar on the project. The context chip should show the proj
Falcon AI returns a category histogram and flags traces where the category looks off given the email content (your wording and counts will vary).
-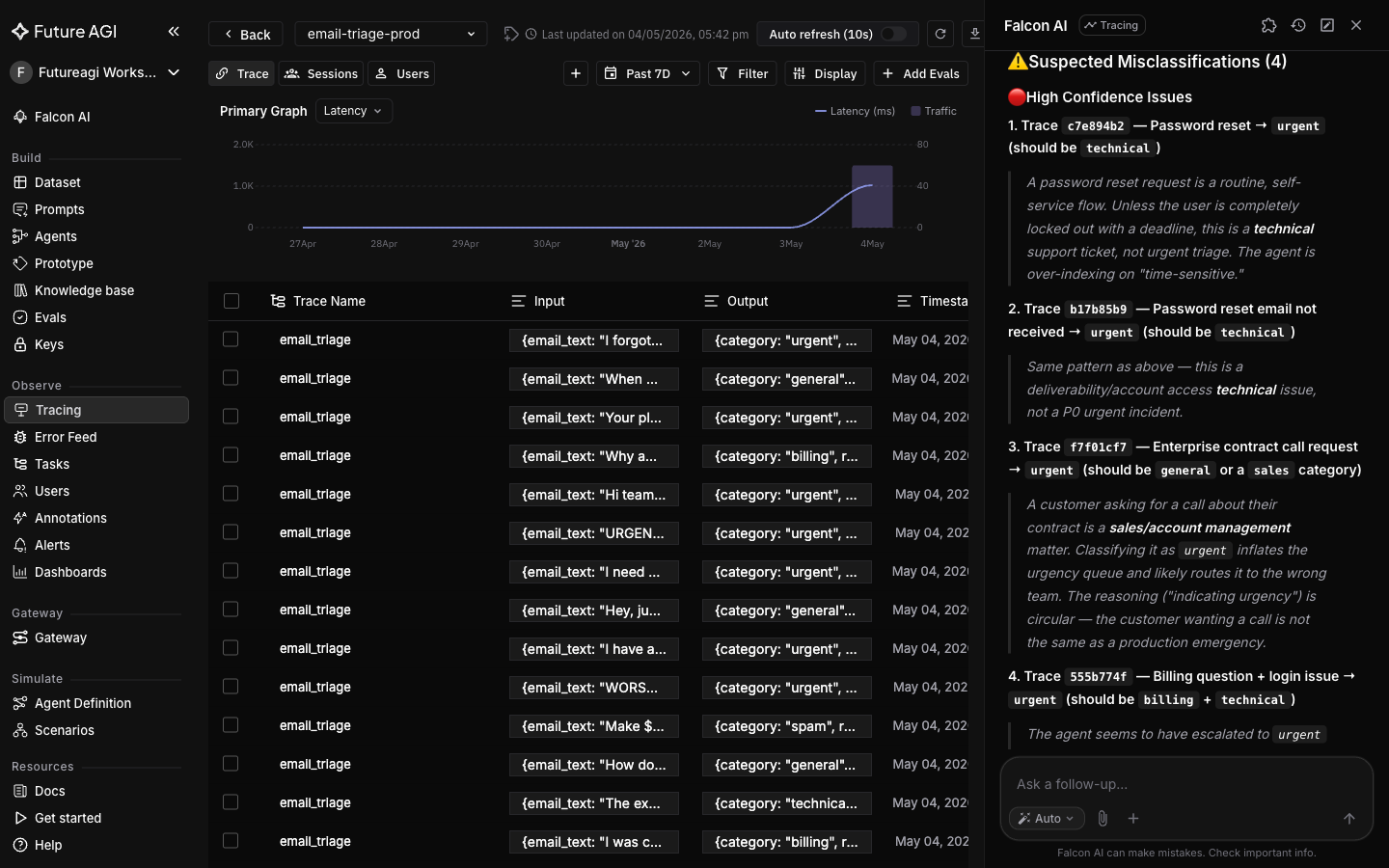 +
+ These flagged misclassifications are a strong starting point, not ground truth. You'll confirm them in a later step.
@@ -127,7 +127,7 @@ These flagged misclassifications are a strong starting point, not ground truth.
Falcon AI orchestrates the underlying dataset tools (such as `create_dataset`, `add_columns`, `add_dataset_rows`) against the traces in context and returns a completion card with a link to the new dataset.
-
These flagged misclassifications are a strong starting point, not ground truth. You'll confirm them in a later step.
@@ -127,7 +127,7 @@ These flagged misclassifications are a strong starting point, not ground truth.
Falcon AI orchestrates the underlying dataset tools (such as `create_dataset`, `add_columns`, `add_dataset_rows`) against the traces in context and returns a completion card with a link to the new dataset.
-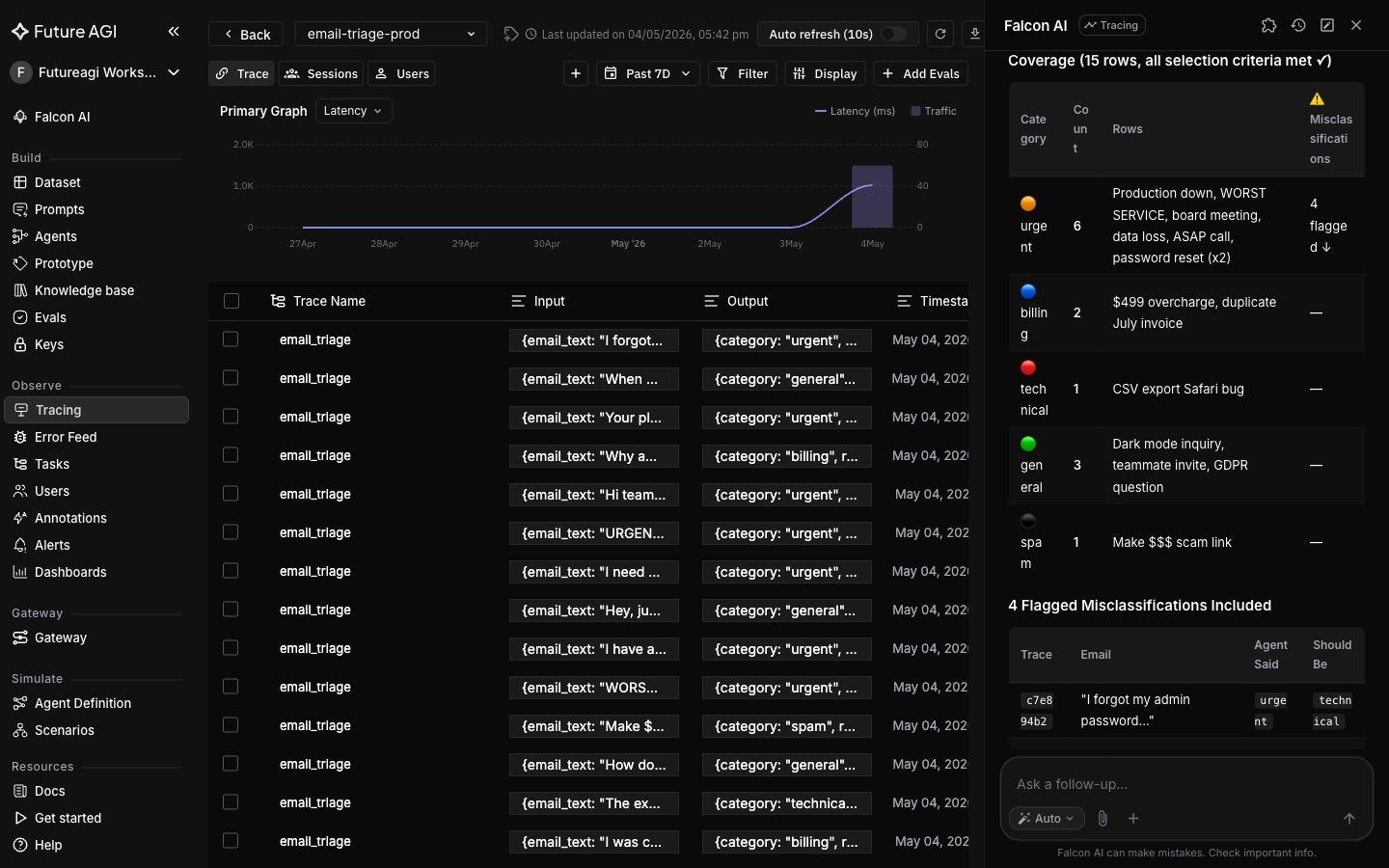 +
+ A dataset that is 90% successes won't catch regressions; one that is 90% failures won't catch false positives. The "at least 2 from each category plus the misclassifications" rule gives both classes meaningful coverage.
@@ -140,7 +140,7 @@ A dataset that is 90% successes won't catch regressions; one that is 90% failure
Falcon AI populates both columns per row. Expect a split between confident `expected_category` values and a few rows tagged `NEEDS_REVIEW`.
-
A dataset that is 90% successes won't catch regressions; one that is 90% failures won't catch false positives. The "at least 2 from each category plus the misclassifications" rule gives both classes meaningful coverage.
@@ -140,7 +140,7 @@ A dataset that is 90% successes won't catch regressions; one that is 90% failure
Falcon AI populates both columns per row. Expect a split between confident `expected_category` values and a few rows tagged `NEEDS_REVIEW`.
-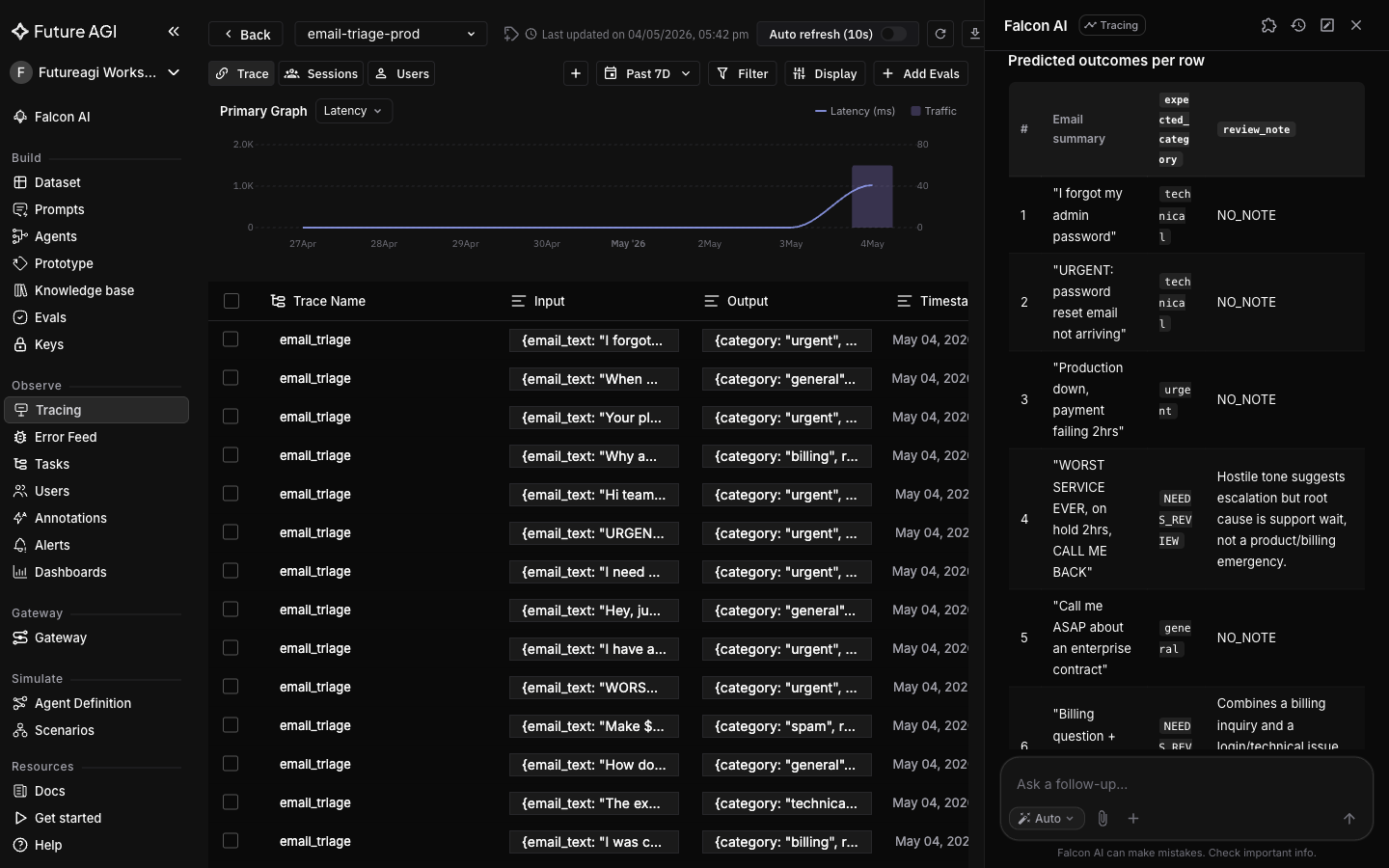 +
+ Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REVIEW` row, and decide based on your team's routing rules. Edit the rows in the UI or ask Falcon AI to update them.
@@ -151,7 +151,7 @@ Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REV
> Run an evaluation on `email-triage-eval-v1` that checks whether `predicted_category` exactly matches `expected_category` for each row. Use the eval template from this workspace that best fits a string-equality check between two columns.
-
Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REVIEW` row, and decide based on your team's routing rules. Edit the rows in the UI or ask Falcon AI to update them.
@@ -151,7 +151,7 @@ Open the dataset in **Datasets → email-triage-eval-v1**, click each `NEEDS_REV
> Run an evaluation on `email-triage-eval-v1` that checks whether `predicted_category` exactly matches `expected_category` for each row. Use the eval template from this workspace that best fits a string-equality check between two columns.
-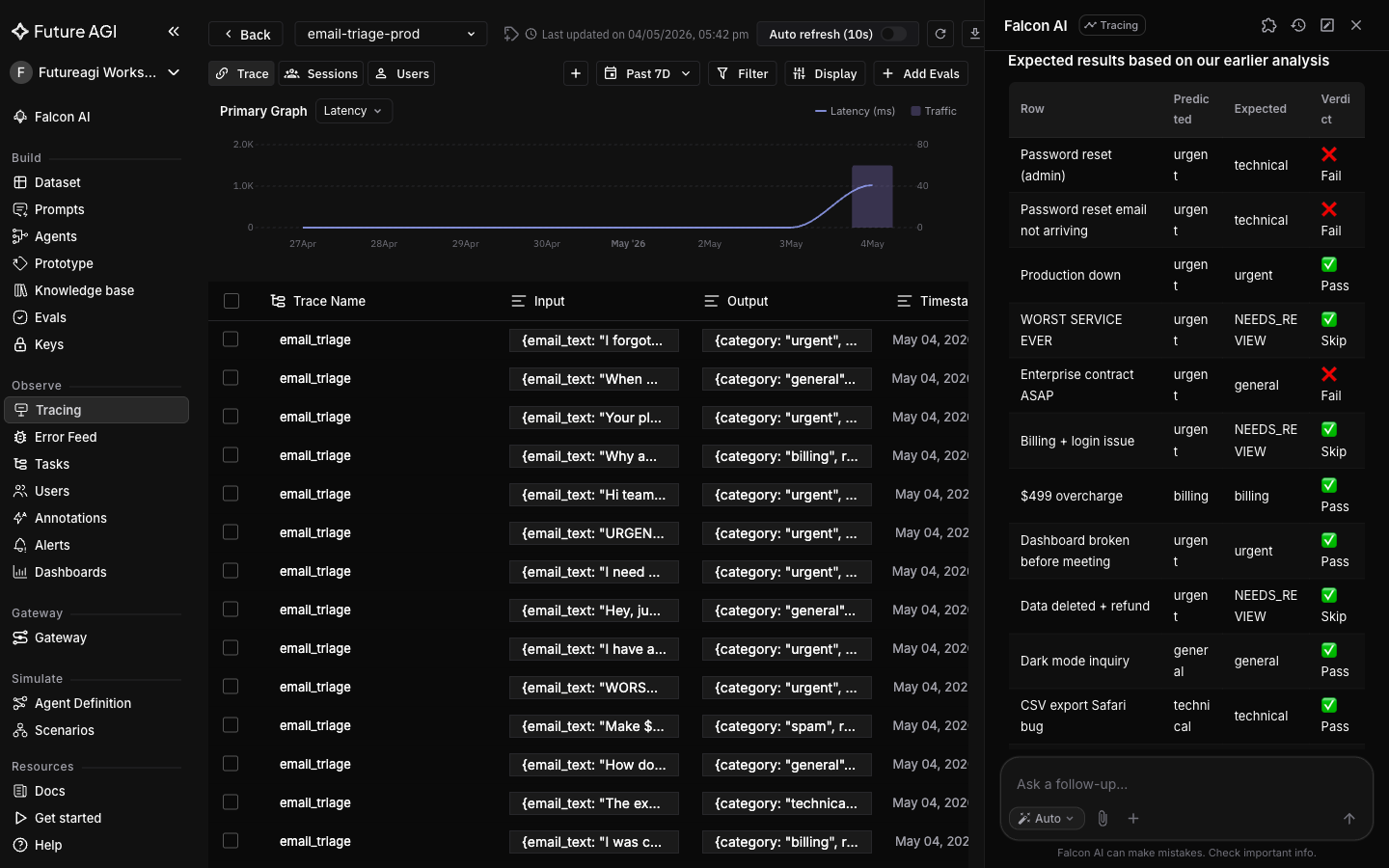 +
+ Both the pass pattern and the fail pattern are what you want. A regression test where every row passes is not testing anything; one where every row fails is just noisy. The dataset now has compounding value: any future prompt change can be re-scored against it in one chat message.
Both the pass pattern and the fail pattern are what you want. A regression test where every row passes is not testing anything; one where every row fails is just noisy. The dataset now has compounding value: any future prompt change can be re-scored against it in one chat message.
 -
- +
+