diff --git a/src/content/_meta.ts b/src/content/_meta.ts
index 20ee871..56556a2 100644
--- a/src/content/_meta.ts
+++ b/src/content/_meta.ts
@@ -17,8 +17,10 @@ const meta: MetaRecord = {
title: 'Quickstart',
theme: {},
},
- 'open-source': 'Open source edition',
- 'cloud-offer': 'Cloud offer',
+ 'run-locally': 'Run locally',
+ 'run-on-lightpanda-cloud': 'Run on Lightpanda Cloud',
+ usage: 'Usage',
+ guides: 'Guides',
}
export default meta
diff --git a/src/content/cloud-offer/tools/cdp.mdx b/src/content/cloud-offer/tools/cdp.mdx
deleted file mode 100644
index f23f296..0000000
--- a/src/content/cloud-offer/tools/cdp.mdx
+++ /dev/null
@@ -1,146 +0,0 @@
----
-title: CDP
-description: Connect to Lightpanda Cloud offer using Chrome Devtool Protocol.
----
-
-# Chrome Devtool Protocol
-
-Use the [Chrome Devtool Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP) to connect to browsers.
-Most of existing tools to control a browser like Puppeteer, Playwright or chromedp are compatible with CDP.
-
-## Usage
-
-Depending on your location, you can connect to the CDP using the url
-`wss://euwest.cloud.lightpanda.io/ws` or `wss//uswest.cloud.lightpanda.io/ws`.
-
-You have to add your token as query string parameter: `token=YOUR_TOKEN`.
-
-```text copy
-// Server in west europe
-wss://euwest.cloud.lightpanda.io/ws?token=TOKEN
-```
-
-```text copy
-// Server in west US
-wss://uswest.cloud.lightpanda.io/ws?token=TOKEN
-```
-
-### Options
-
-The CDP url takes options to configure the browser as query string parameters.
-
-#### Browser
-
-By default, the CDP serves [Lightpanda browsers](https://github.com/lightpanda-io/browser).
-But you can select Google Chrome browser using `browser=chrome` parameter in the url.
-`browser=lightpanda` forces the usage of Lightpanda browser.
-
-```text copy
-wss://euwest.cloud.lightpanda.io/ws?browser=chrome&token=TOKEN
-```
-#### Proxies
-
-**fast_dc**
-
-You can configure proxies for your browser with `proxy` query string parameter.
-By default, the proxy used is `fast_dc`, a single shared datacenter IP.
-
-**datacenter**
-
-Set `datacenter` proxy to use a pool of shared datacenter IPs. The IPs rotate automatically.
-
-`datacenter` proxy accepts an optional `country` query string parameter, a two letter country code.
-
-Example using a german IP with a lightpanda browser.
-
-```text copy
-wss://euwest.cloud.lightpanda.io/ws?proxy=datacenter&country=de&token=TOKEN
-```
-
-Please [contact us](mailto:hello@lightpanda.io) to get access to additional proxies for your specific use case or to configure your own proxy with Lightpanda Cloud offer.
-
-
-## Connection examples
-
-You can find more script examples in the [demo](https://github.com/lightpanda-io/demo/) repository.
-
-### Playwright
-
-Use Lightpanda CDP with [Playwright](https://playwright.dev/).
-
-
-```js copy
-import playwright from "playwright-core";
-
-const browser = await playwright.chromium.connectOverCDP(
- "wss://euwest.cloud.lightpanda.io/ws?token=TOKEN",
-);
-const context = await browser.newContext();
-const page = await context.newPage();
-
-//...
-
-await page.close();
-await context.close();
-await browser.close();
-```
-
-More examples in [demo/playwright](https://github.com/lightpanda-io/demo/tree/main/playwright).
-
-### Puppeteer
-
-Use Lightpanda CDP with [Puppeteer](https://pptr.dev/).
-
-```js copy
-import puppeteer from 'puppeteer-core';
-
-const browser = await puppeteer.connect({
- browserWSEndpoint: "wss://euwest.cloud.lightpanda.io/ws?token=TOKEN",
-});
-const context = await browser.createBrowserContext();
-const page = await context.newPage();
-
-// ...
-
-await page.close();
-await context.close();
-await browser.disconnect();
-```
-
-More examples in [demo/puppeteer](https://github.com/lightpanda-io/demo/tree/main/puppeteer).
-
-### Chromedp
-
-Use Lightpanda CDP with [Chromedp](https://github.com/chromedp/chromedp).
-
-```go copy
-package main
-
-import (
- "context"
- "log"
-
- "github.com/chromedp/chromedp"
-)
-
-func main() {
- ctx, cancel := chromedp.NewRemoteAllocator(context.Background(),
- "wss://euwest.cloud.lightpanda.io/ws?token=TOKEN", chromedp.NoModifyURL,
- )
- defer cancel()
-
- ctx, cancel = chromedp.NewContext(ctx)
- defer cancel()
-
- var title string
- if err := chromedp.Run(ctx,
- chromedp.Navigate("https://lightpanda.io"),
- chromedp.Title(&title),
- ); err != nil {
- log.Fatalf("Failed getting title of lightpanda.io: %v", err)
- }
-
- log.Println("Got title of:", title)
-}
-```
-More examples in [demo/chromedp](https://github.com/lightpanda-io/demo/tree/main/chromedp).
diff --git a/src/content/cloud-offer/tools/mcp.mdx b/src/content/cloud-offer/tools/mcp.mdx
deleted file mode 100644
index 14b6c5e..0000000
--- a/src/content/cloud-offer/tools/mcp.mdx
+++ /dev/null
@@ -1,40 +0,0 @@
----
-title: MCP
-description: Control Lightpanda's cloud offer using Model Context Protocol
----
-
-# Model Context Protocol
-
-Use the [Model Context Protocol](https://modelcontextprotocol.io) (MCP) to
-easily control Lightpanda browser with your AI applications.
-
-## Usage
-
-The Lightpanda MCP service supports only [SSE](https://modelcontextprotocol.io/specification/2024-11-05/basic/transports#http-with-sse) transport.
-
-Depending on your location, you can connect to the MCP using the url
-`wss://euwest.cloud.lightpanda.io/mcp/sse` or `wss//uswest.cloud.lightpanda.io/mcp/sse`.
-
-### Authentication
-
-An authentication is required, you can either pass your token with the `token` query string parameter in the url, or use the `Authorization: Bearer` HTTP header.
-
-Example with the query string.
-```text copy
-https://euwest.cloud.lightpanda.io/mcp/sse?token=TOKEN
-```
-
-Example with the Bearer HTTP header.
-```text copy
-https://euwest.cloud.lightpanda.io/mcp/sse
-Authorization: Bearer TOKEN
-```
-
-## Tools
-
-* `search` Search a term on web search engine and get the search results.
-* `goto` Navigate to a specified URL and load the page in memory so it can be reused later for info extraction.
-* `markdown` Get the page in memory content in markdown format. Run a goto before getting markdown.
-* `links` Extract all links from the page in memory. Run a goto before getting links.
-
-For more advanced use cases, you can use [CDP](/cloud-offer/tools/cdp) connection with [Playwright MCP](https://github.com/microsoft/playwright-mcp).
diff --git a/src/content/guides/_meta.ts b/src/content/guides/_meta.ts
new file mode 100644
index 0000000..88c2983
--- /dev/null
+++ b/src/content/guides/_meta.ts
@@ -0,0 +1,11 @@
+import type { MetaRecord } from 'nextra'
+
+const meta: MetaRecord = {
+ 'retrieve-an-html-webpage': 'Retrieve an HTML webpage',
+ 'markdown-axtree': 'Get a markdown version',
+ 'interact-with-a-webpage': 'Interact with a webpage',
+ 'use-stagehand': 'Use Stagehand',
+ 'use-hermes': 'Use Hermes Agent',
+}
+
+export default meta
diff --git a/src/content/quickstart/build-your-first-extraction-script.mdx b/src/content/guides/interact-with-a-webpage.mdx
similarity index 64%
rename from src/content/quickstart/build-your-first-extraction-script.mdx
rename to src/content/guides/interact-with-a-webpage.mdx
index b1954a3..24c3794 100644
--- a/src/content/quickstart/build-your-first-extraction-script.mdx
+++ b/src/content/guides/interact-with-a-webpage.mdx
@@ -1,62 +1,70 @@
---
-title: Build your first data extraction script
-description: Learn how to scrape Hackernews search page.
+title: Interact with a webpage
+description: Learn how to interact with a dynamic webpage by typing, submitting a form, and extracting data with Lightpanda.
---
import { Tabs } from 'nextra/components'
+import { Callout } from 'nextra/components'
-# 3. Extract data
+# Interact with a webpage
-We will now use the browser to run a search on the [HackerNews
-website](https://news.ycombinator.com/). We need Lightpanda here because the
-website uses XHR requests to display search results. We will also run query
-selectors directly in the browser to extract
-and structure the data.
+In this guide, you'll use Lightpanda to run a search on [HackerNews](https://news.ycombinator.com/), wait for dynamic results to load, and extract structured data from the page.
-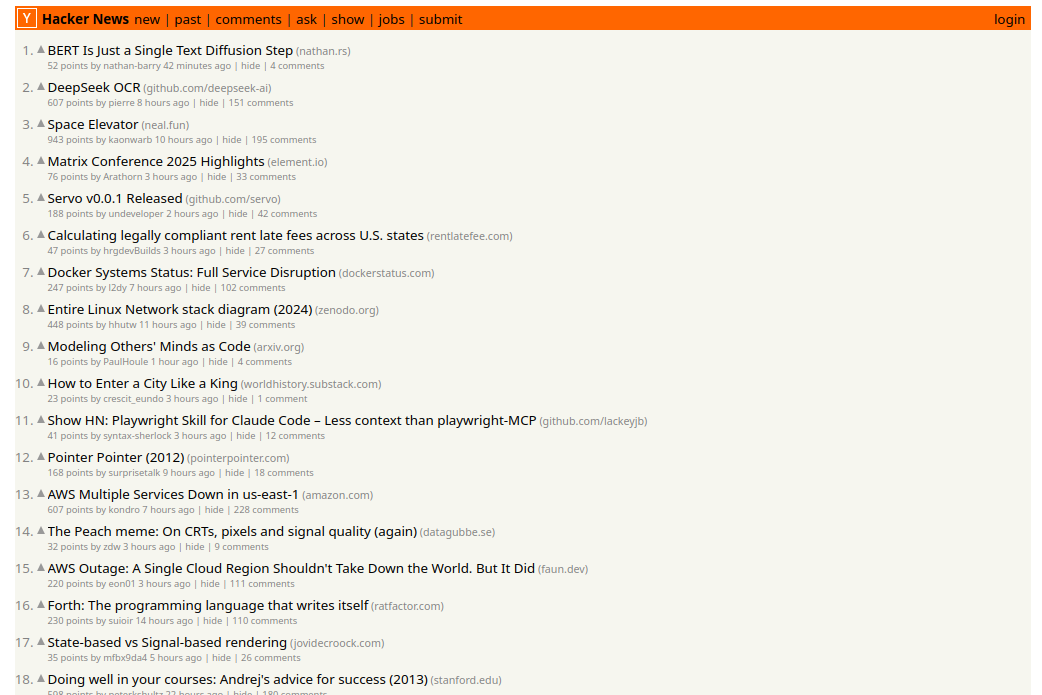
+This example requires Lightpanda because HackerNews uses XHR requests to display search results — raw HTML fetching wouldn't capture them.
-## Navigate and search
+
+ This guide uses **CDP locally**. Lightpanda is started as a local process via the `@lightpanda/browser` npm package. To connect from the cloud or use a different client, see the [Usage / CDP](/usage/cdp/puppeteer) section.
+
+
+## Prerequisites
-Similar to the Wikipedia example, edit `index.js` to navigate to HackerNews:
+Install the [`puppeteer-core`](https://www.npmjs.com/package/puppeteer-core) *or* [`playwright-core`](https://www.npmjs.com/package/playwright-core) npm package.
-```javascript copy
- await page.goto("https://news.ycombinator.com/");
+```sh copy
+npm install --save puppeteer-core @lightpanda/browser
```
-```javascript copy
- await page.goto("https://news.ycombinator.com/");
+```sh copy
+npm install --save playwright-core @lightpanda/browser
```
-Type the term lightpanda in the search input at the bottom of the page and
-press the Enter key to submit the search:
+## Navigate and search
+
+Navigate to HackerNews, type a search term, and press Enter:
```javascript copy
- await page.type('input[name="q"]','lightpanda');
+ await page.goto("https://news.ycombinator.com/");
+
+ await page.type('input[name="q"]', 'lightpanda');
await page.keyboard.press('Enter');
```
```javascript copy
+ await page.goto("https://news.ycombinator.com/");
+
await page.locator('input[name="q"]').fill('lightpanda');
await page.keyboard.press('Enter');
```
-Wait for the search results to be displayed, with a timeout limit of 5 seconds:
+## Wait for results
+
+Wait for the search results to appear, with a 5 second timeout:
```javascript copy
await page.waitForFunction(() => {
- return document.querySelector('.Story_container') != null;
- }, {timeout: 5000});
+ return document.querySelector('.Story_container') != null;
+ }, { timeout: 5000 });
```
@@ -68,54 +76,46 @@ Wait for the search results to be displayed, with a timeout limit of 5 seconds:
## Extract the data
-We will loop over the search results to extract the title, the URL, and a list
-of metadata including the author, the number of points, and comments:
+Loop over the results to extract the title, URL, and metadata for each story:
```javascript copy
- // Loop over search results to extract data.
const res = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.Story_container')).map(row => {
return {
- // Extract the title.
title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
return row.textContent;
}),
}
});
});
+
+ console.log(res);
```
```javascript copy
- // Loop over search results to extract data.
const res = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.Story_container')).map(row => {
return {
- // Extract the title.
title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
return row.textContent;
}),
}
});
});
+
+ console.log(res);
```
-## The final script
-
-Here is the full version of index.js updated to run the search and extract
-results:
+## Full script
@@ -146,27 +146,21 @@ const puppeteeropts = {
// Go to hackernews home page.
await page.goto("https://news.ycombinator.com/");
- // Find the search box at the bottom of the page and type the term lightpanda
- // to search.
- await page.type('input[name="q"]','lightpanda');
- // Press enter key to run the search.
+ // Type the search term and submit.
+ await page.type('input[name="q"]', 'lightpanda');
await page.keyboard.press('Enter');
- // Wait until the search results are loaded on the page, with a 5 seconds
- // timeout limit.
+ // Wait until the search results are loaded.
await page.waitForFunction(() => {
- return document.querySelector('.Story_container') != null;
- }, {timeout: 5000});
+ return document.querySelector('.Story_container') != null;
+ }, { timeout: 5000 });
// Loop over search results to extract data.
const res = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.Story_container')).map(row => {
return {
- // Extract the title.
title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
return row.textContent;
}),
@@ -174,7 +168,6 @@ const puppeteeropts = {
});
});
- // Display the result.
console.log(res);
// Disconnect Puppeteer.
@@ -209,7 +202,7 @@ const playwrightopts = {
// Start Lightpanda browser in a separate process.
const proc = await lightpanda.serve(lpdopts);
- // Connect using Playwright's chromium driver to the browser.
+ // Connect Playwright's chromium driver to the browser.
const browser = await chromium.connectOverCDP(playwrightopts);
const context = await browser.newContext({});
const page = await context.newPage();
@@ -217,25 +210,19 @@ const playwrightopts = {
// Go to hackernews home page.
await page.goto("https://news.ycombinator.com/");
- // Find the search box at the bottom of the page and type the term lightpanda
- // to search.
+ // Type the search term and submit.
await page.locator('input[name="q"]').fill('lightpanda');
- // Press enter key to run the search.
await page.keyboard.press('Enter');
- // Wait until the search results are loaded on the page, with a 5 seconds
- // timeout limit.
+ // Wait until the search results are loaded.
await page.waitForSelector('.Story_container', { timeout: 5000 });
// Loop over search results to extract data.
const res = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.Story_container')).map(row => {
return {
- // Extract the title.
title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
return row.textContent;
}),
@@ -243,7 +230,6 @@ const playwrightopts = {
});
});
- // Display the result.
console.log(res);
// Disconnect Playwright.
@@ -260,13 +246,12 @@ const playwrightopts = {
-## Run the script
-
-You can run it to see the result immediately:
+## Run it
```sh copy
node index.js
```
+
```sh
$ node index.js
🐼 Running Lightpanda's CDP server… { pid: 598201 }
@@ -281,27 +266,6 @@ $ node index.js
url: 'https://news.ycombinator.com/item?id=42812859',
meta: [ '154 points', 'tosh', '9 months ago', '1 comments' ]
},
- {
- title: 'Show HN: Lightpanda, an open-source headless browser in Zig',
- url: 'https://news.ycombinator.com/item?id=42430629',
- meta: [ '7 points', 'fbouvier', '10 months ago', '0 comments' ]
- },
- {
- title: 'Lightpanda: Fast headless browser from scratch in Zig for AI and automation',
- url: 'https://news.ycombinator.com/item?id=44900394',
- meta: [ '5 points', 'lioeters', '2 months ago', '0 comments' ]
- },
- {
- title: 'Lightpanda – The Headless Browser',
- url: 'https://news.ycombinator.com/item?id=42745150',
- meta: [ '4 points', 'vladkens', '9 months ago', '2 comments' ]
- },
- {
- title: 'Lightpanda raises pre-seed to develop first browser built for machines and AI',
- url: 'https://news.ycombinator.com/item?id=44263271',
- meta: [ '1 points', 'cpeterso', '4 months ago', '0 comments' ]
- }
+ ...
]
```
-
-### Step 4: [Go to production](/quickstart/go-to-production-with-lightpanda-cloud)
diff --git a/src/content/open-source/guides/markdown-axtree.mdx b/src/content/guides/markdown-axtree.mdx
similarity index 97%
rename from src/content/open-source/guides/markdown-axtree.mdx
rename to src/content/guides/markdown-axtree.mdx
index 8fa2d06..e08e56a 100644
--- a/src/content/open-source/guides/markdown-axtree.mdx
+++ b/src/content/guides/markdown-axtree.mdx
@@ -3,11 +3,16 @@ title: Markdown and AXTree
description: Convert any web page to clean, token-efficient Markdown and Accessibility tree directly from the browser, after JavaScript execution.
---
import { Tabs } from 'nextra/components'
+import { Callout } from 'nextra/components'
# Markdown and AXTree
Lightpanda outputs web page content as Markdown and Accessibility tree directly from its browser engine, after JavaScript execution. No external HTML-to-Markdown converter needed.
+
+ This guide covers **three local approaches**: CLI, CDP, and MCP. For cloud usage, see the [Usage](/usage/cdp/puppeteer) section.
+
+
## Overview
Three ways to get Markdown and Accessibility tree from any web page:
@@ -324,7 +329,7 @@ The MCP server exposes `markdown` and `semantic_tree` tools.
| markdown | Get the page content in markdown format. If a url is provided, it navigates to that url first. |
| semantic_tree | Get the page content as a simplified semantic DOM tree for AI reasoning. If a url is provided, it navigates to that url first. |
-> For full MCP server documentation — tools, resources, handshake protocol, agent configuration, and HTTP transport — see the [MCP server guide](/open-source/guides/mcp-server).
+> For full MCP server documentation — tools, resources, handshake protocol, agent configuration, and HTTP transport — see the [MCP server guide](/guides/mcp-server).
## References
diff --git a/src/content/quickstart/your-first-test.mdx b/src/content/guides/retrieve-an-html-webpage.mdx
similarity index 53%
rename from src/content/quickstart/your-first-test.mdx
rename to src/content/guides/retrieve-an-html-webpage.mdx
index 9a51b12..2ab7b31 100644
--- a/src/content/quickstart/your-first-test.mdx
+++ b/src/content/guides/retrieve-an-html-webpage.mdx
@@ -1,189 +1,79 @@
---
-title: Your first test
-description: Learn what is Lightpanda browser and run your first scrapping script.
+title: Retrieve an HTML webpage
+description: Learn how to navigate to a webpage and extract data using Puppeteer or Playwright with Lightpanda.
---
import { Tabs } from 'nextra/components'
import { Callout } from 'nextra/components'
-# 2. Your first test
+# Retrieve an HTML webpage
-Lightpanda is a headless browser built from scratch. Unlike Headless Chrome, it
-has no UI or graphical rendering for humans, which allows it to start instantly
-and execute pages up to 10x faster.
+In this guide, you'll connect a CDP client to Lightpanda and extract all reference links from a [Wikipedia page](https://en.wikipedia.org/wiki/Web_browser).
-Unlike [curl](https://curl.se/), which only fetches raw HTML, Lightpanda can
-execute JavaScript and run query selectors directly in the browser.
-
-It's ideal for crawling, testing, and running AI agents that need to interact
-with dynamic web pages, and it’s fully compatible with libraries like
-[Puppeteer](https://pptr.dev/) and [Playwright](https://playwright.dev/).
+
+ This guide uses **CDP locally**. Lightpanda is started as a local process via the `@lightpanda/browser` npm package. To connect from the cloud or use a different client, see the [Usage / CDP](/usage/cdp/puppeteer) section.
+
-In this example, you’ll connect CDP client, [Puppeteer](https://pptr.dev/) or [Playwright](https://playwright.dev/) to Lightpanda
-and extract all reference links from a [Wikipedia
-page](https://www.wikipedia.org/).
+Unlike [curl](https://curl.se/), which only fetches raw HTML, Lightpanda executes JavaScript and runs query selectors directly in the browser — making it suitable for dynamic pages.
-## Connect CDP Client to Lightpanda
+## Prerequisites
Install the [`puppeteer-core`](https://www.npmjs.com/package/puppeteer-core) *or* [`playwright-core`](https://www.npmjs.com/package/playwright-core) npm package.
- Unlike `puppeteer` and `playwright` npm packages,
- `puppeteer-core` and `playwright-core` don't download a Chromium browser.
+ Unlike `puppeteer` and `playwright`, `puppeteer-core` and `playwright-core` don't download a Chromium browser.
```sh copy
-npm install -save puppeteer-core
+npm install --save puppeteer-core @lightpanda/browser
```
```sh copy
-npm install -save playwright-core
-```
-
-
-
-Edit your `index.js` to connect to Lightpanda:
-
-
-
-```javascript copy
-'use strict'
-
-import { lightpanda } from '@lightpanda/browser';
-import puppeteer from 'puppeteer-core';
-
-const lpdopts = {
- host: '127.0.0.1',
- port: 9222,
-};
-
-const puppeteeropts = {
- browserWSEndpoint: 'ws://' + lpdopts.host + ':' + lpdopts.port,
-};
-
-(async () => {
- // Start Lightpanda browser in a separate process.
- const proc = await lightpanda.serve(lpdopts);
-
- // Connect Puppeteer to the browser.
- const browser = await puppeteer.connect(puppeteeropts);
- const context = await browser.createBrowserContext();
- const page = await context.newPage();
-
- // Do your magic ✨
- console.log("CDP connection is working");
-
- // Disconnect Puppeteer.
- await page.close();
- await context.close();
- await browser.disconnect();
-
- // Stop Lightpanda browser process.
- proc.stdout.destroy();
- proc.stderr.destroy();
- proc.kill();
-})();
-```
-
-
-```javascript copy
-'use strict'
-
-import { lightpanda } from '@lightpanda/browser';
-import { chromium } from 'playwright-core';
-
-const lpdopts = {
- host: '127.0.0.1',
- port: 9222,
-};
-
-const playwrightopts = {
- endpointURL: 'ws://' + lpdopts.host + ':' + lpdopts.port,
-};
-
-(async () => {
- // Start Lightpanda browser in a separate process.
- const proc = await lightpanda.serve(lpdopts);
-
- // Connect Playwright's chromium driver to the browser.
- const browser = await chromium.connectOverCDP(playwrightopts);
- const context = await browser.newContext({});
- const page = await context.newPage();
-
- // Do your magic ✨
- console.log("CDP connection is working");
-
- // Disconnect Puppeteer.
- await page.close();
- await context.close();
- await browser.close();
-
- // Stop Lightpanda browser process.
- proc.stdout.destroy();
- proc.stderr.destroy();
- proc.kill();
-})();
+npm install --save playwright-core @lightpanda/browser
```
-Run the script to test the connection between Puppeteer or Playwright and Lightpanda:
+## Navigate and extract
-```sh copy
-node index.js
-```
-```sh
-$ node index.js
-🐼 Running Lightpanda's CDP server... { pid: 31371 }
-CDP connection is working
-```
-
-## Extract all reference links from Wikipedia
-
-Update `index.js` using `page.goto` to navigate to a Wikipedia page and extract
-all the reference links:
+Use `page.goto` to navigate to the Wikipedia page, then run a query selector to extract all external reference links:
```javascript copy
// Go to Wikipedia page.
await page.goto("https://en.wikipedia.org/wiki/Web_browser");
-```
-
-
-```javascript copy
- // Go to Wikipedia page.
- await page.goto("https://en.wikipedia.org/wiki/Web_browser");
-```
-
-
-
-Execute a query selector on the browser to extract the links:
-
-
-```javascript copy
// Extract all links from the references list of the page.
const reflist = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.references a.external')).map(row => {
return row.getAttribute('href');
});
});
+
+ // Display the result.
+ console.log("all reference links", reflist);
```
```javascript copy
+ // Go to Wikipedia page.
+ await page.goto("https://en.wikipedia.org/wiki/Web_browser");
+
// Extract all links from the references list of the page.
const reflist = await page.locator('.references a.external').evaluateAll(links =>
links.map(link => link.getAttribute('href'))
);
+
+ // Display the result.
+ console.log("all reference links", reflist);
```
-Here’s the full `index.js` file:
+## Full script
@@ -256,7 +146,7 @@ const playwrightopts = {
// Start Lightpanda browser in a separate process.
const proc = await lightpanda.serve(lpdopts);
- // Connect using Playwright's chromium driver to the browser.
+ // Connect Playwright's chromium driver to the browser.
const browser = await chromium.connectOverCDP(playwrightopts);
const context = await browser.newContext({});
const page = await context.newPage();
@@ -286,9 +176,8 @@ const playwrightopts = {
-## Execute the link extraction
+## Run it
-Execute index.js to see the links directly in your console:
```sh copy
node index.js
```
@@ -302,6 +191,6 @@ all reference links [
'https://web.archive.org/web/20240523140912/https://www.internetworldstats.com/stats.htm',
'https://www.internetworldstats.com/stats.htm',
'https://www.reference.com/humanities-culture/purpose-browser-e61874e41999ede',
+ ...
+]
```
-
-### Step 3: [Extract data](/quickstart/build-your-first-extraction-script)
diff --git a/src/content/open-source/guides/use-hermes.mdx b/src/content/guides/use-hermes.mdx
similarity index 96%
rename from src/content/open-source/guides/use-hermes.mdx
rename to src/content/guides/use-hermes.mdx
index 191a08a..6c97c10 100644
--- a/src/content/open-source/guides/use-hermes.mdx
+++ b/src/content/guides/use-hermes.mdx
@@ -14,7 +14,7 @@ When configured to use Lightpanda, Hermes will route browser actions through Lig
- Hermes Agent `v0.13.0` or later
- Lightpanda installed and on your `PATH`
-If you don't yet have Lightpanda installed, follow the [installation guide](/docs/open-source/installation).
+If you don't yet have Lightpanda installed, follow the [installation guide](/docs/run-locally/installation).
## Install Hermes
@@ -99,4 +99,4 @@ The current set of actions supported by Lightpanda inside Hermes covers the core
- [Hermes Agent documentation](https://hermes-agent.nousresearch.com/docs/)
- [Pull request that added Lightpanda support to Hermes](https://github.com/NousResearch/hermes-agent/pull/7144)
-- [Lightpanda installation guide](/docs/open-source/installation)
+- [Lightpanda installation guide](/docs/run-locally/installation)
diff --git a/src/content/open-source/guides/use-stagehand.mdx b/src/content/guides/use-stagehand.mdx
similarity index 90%
rename from src/content/open-source/guides/use-stagehand.mdx
rename to src/content/guides/use-stagehand.mdx
index 0ac5340..d3730f9 100644
--- a/src/content/open-source/guides/use-stagehand.mdx
+++ b/src/content/guides/use-stagehand.mdx
@@ -2,6 +2,7 @@
title: Use Stagehand
description: Here is how to use Stagehand framwork with the Lightpanda browser.
---
+import { Callout } from 'nextra/components'
# Use Stagehand with Lightpanda
@@ -15,6 +16,10 @@ Since Lightpanda supports [Accessibilty
tree](https://github.com/lightpanda-io/browser/pull/1308), you can use it
instead of Chrome with your Stagehand script.
+
+ This guide uses **CDP locally**. Lightpanda is started as a local process via the `@lightpanda/browser` npm package. For cloud usage, see the [Usage / CDP](/usage/cdp/puppeteer) section.
+
+
## Install the Lightanda and Stagehand dependencies
If not set, create a new npm project and install Stagehand depencies.
diff --git a/src/content/open-source/_meta.ts b/src/content/open-source/_meta.ts
deleted file mode 100644
index cb58ee0..0000000
--- a/src/content/open-source/_meta.ts
+++ /dev/null
@@ -1,15 +0,0 @@
-import type { MetaRecord } from 'nextra'
-
-const meta: MetaRecord = {
- installation: 'Installation',
- usage: 'Usage',
- guides: {
- title: 'Guides',
- theme: {
- collapsed: false,
- },
- },
- 'systems-requirements': 'Systems requirements',
-}
-
-export default meta
diff --git a/src/content/open-source/installation.mdx b/src/content/open-source/installation.mdx
deleted file mode 100644
index 8498f2e..0000000
--- a/src/content/open-source/installation.mdx
+++ /dev/null
@@ -1,120 +0,0 @@
----
-title: Installation
-description: You can download the last binary from the nightly builds for Linux x86_64 and MacOS aarch64 or use Docker image.
----
-import { Callout } from 'nextra/components'
-
-# Installation
-
-## One-liner installer
-
-For Linux or MacOSx users, you can install Lightpanda with following command.
-For Windows, take a look at the [dedicated section](#windows--wsl2).
-
-```bash copy
-curl -fsSL https://pkg.lightpanda.io/install.sh | bash
-```
-
-
-`curl`, `jq` and `sha256sum` are required to install Lightpanda with the
-one-liner installer.
-
-
-By default the installer installs the last nightly build.
-But you can pick a specific release:
-
-```bash copy
-curl -fsSL https://pkg.lightpanda.io/install.sh | bash -s "v0.2.5"
-```
-
-## Install from Docker
-
-Lightpanda provides [official Docker
-images](https://hub.docker.com/r/lightpanda/browser) for both Linux amd64 and
-arm64 architectures.
-
-The following command fetches the Docker image and starts a new container exposing Lightpanda's CDP server on port `9222`.
-
-```sh copy
-docker run -d --name lightpanda -p 127.0.0.1:9222:9222 lightpanda/browser:nightly
-```
-
-## Install from package manager
-
-### Homebrew
-
-Install the last nightly using Homebrew.
-
-```sh copy
-brew install lightpanda-io/browser/lightpanda
-```
-
-### Arch Linux User Repository
-
-```sh copy
-yay -S lightpanda-bin
-```
-
-You can alternatively use the last nightly version with:
-```sh copy
-yay -S lightpanda-nightly-bin
-```
-
-### Debian/Ubuntu
-
-Starting `0.3.0`, a `.deb` is available with each [tagged
-release](https://github.com/lightpanda-io/browser/releases).
-
-## Install manually from the nightly builds
-
-The latest binary can be downloaded from the [nightly
-builds](https://github.com/lightpanda-io/browser/releases/tag/nightly) for
-Linux and MacOS.
-
-### Linux x86_64
-```bash copy
-curl -L -o lightpanda \
- https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-linux && \
- chmod a+x ./lightpanda
-```
-
-### Linux aarch64
-```bash copy
-curl -L -o lightpanda \
- https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-aarch64-linux && \
- chmod a+x ./lightpanda
-```
-
-### MacOS aarch64
-```sh copy
-curl -L -o lightpanda \
- https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-aarch64-macos && \
- chmod a+x ./lightpanda
-```
-
-### MacOS x86_64
-```sh copy
-curl -L -o lightpanda \
- https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-macos && \
- chmod a+x ./lightpanda
-```
-
-## Windows + WSL2
-
-The Lightpanda browser is compatible to run on Windows inside WSL (Windows Subsystem for Linux). If WSL has not been installed before follow these steps (for more information see: [MS Windows install WSL](https://learn.microsoft.com/en-us/windows/wsl/install)).
-Install & open WSL + Ubuntu from an **administrator** shell:
- 1. `wsl --install`
- 2. -- restart --
- 3. `wsl --install -d Ubuntu`
- 4. `wsl`
-
-Once WSL and a Linux distribution have been installed the browser can be installed in the same way it is installed for Linux.
-Inside WSL install the Lightpanda browser:
-```bash copy
-curl -L -o lightpanda https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-linux && \
-chmod a+x ./lightpanda
-```
-It is recommended to install clients like Puppeteer on the Windows host.
-
-## Telemetry
-By default, Lightpanda collects and sends usage telemetry. This can be disabled by setting an environment variable `LIGHTPANDA_DISABLE_TELEMETRY=true`. You can read Lightpanda's privacy policy at: [https://lightpanda.io/privacy-policy](https://lightpanda.io/privacy-policy).
diff --git a/src/content/open-source/usage.mdx b/src/content/open-source/usage.mdx
deleted file mode 100644
index 308a011..0000000
--- a/src/content/open-source/usage.mdx
+++ /dev/null
@@ -1,439 +0,0 @@
----
-title: Usage
-description: You can dump an URL manually or start a CDP server.
----
-
-# Usage
-
-Use `./lightpanda help` for all options.
-
-## Fetch a webpage
-
-```sh copy
-./lightpanda fetch --obey-robots --dump html https://demo-browser.lightpanda.io/campfire-commerce/
-```
-```sh
-INFO http : navigate . . . . . . . . . . . . . . . . . . . . [+0ms]
- url = https://demo-browser.lightpanda.io/campfire-commerce/
- method = GET
- reason = address_bar
- body = false
-
-INFO browser : executing script . . . . . . . . . . . . . . [+196ms]
- src = https://demo-browser.lightpanda.io/campfire-commerce/script.js
- kind = javascript
- cacheable = true
-
-INFO http : request complete . . . . . . . . . . . . . . . . [+223ms]
- source = xhr
- url = https://demo-browser.lightpanda.io/campfire-commerce/json/product.json
- status = 200
-
-INFO http : request complete . . . . . . . . . . . . . . . . [+234ms]
- source = xhr
- url = https://demo-browser.lightpanda.io/campfire-commerce/json/reviews.json
- status = 200
-
-```
-
-### Options
-
-### `fetch` command options
-
-```bash
---dump Dumps document to stdout.
- Argument must be 'html', 'markdown', 'semantic_tree', or 'semantic_tree_text'.
- Defaults to no dump.
-
---strip-mode Comma separated list of tag groups to remove from dump
- the dump. e.g. --strip-mode js,css
- - "js" script and link[as=script, rel=preload]
- - "ui" includes img, picture, video, css and svg
- - "css" includes style and link[rel=stylesheet]
- - "full" includes js, ui and css
-
---with-base Add a tag in dump. Defaults to false.
-
---with-frames Includes the contents of iframes. Defaults to false.
-
---wait-ms Wait time in milliseconds.
- Defaults to 5000.
-
---wait-until Wait until the specified event.
- Supported events: load, domcontentloaded, networkidle, done.
- Defaults to 'done'.
-
---insecure-disable-tls-host-verification
- Disables host verification on all HTTP requests. This is an
- advanced option which should only be set if you understand
- and accept the risk of disabling host verification.
-
---obey-robots
- Fetches and obeys the robots.txt (if available) of the web pages
- we make requests towards.
- Defaults to false.
-
---http-proxy The HTTP proxy to use for all HTTP requests.
- A username:password can be included for basic authentication.
- Defaults to none.
-
---proxy-bearer-token
- The to send for bearer authentication with the proxy
- Proxy-Authorization: Bearer
-
---http-max-concurrent
- The maximum number of concurrent HTTP requests.
- Defaults to 10.
-
---http-max-host-open
- The maximum number of open connection to a given host:port.
- Defaults to 4.
-
---http-connect-timeout
- The time, in milliseconds, for establishing an HTTP connection
- before timing out. 0 means it never times out.
- Defaults to 0.
-
---http-timeout
- The maximum time, in milliseconds, the transfer is allowed
- to complete. 0 means it never times out.
- Defaults to 10000.
-
---http-max-response-size
- Limits the acceptable response size for any request
- (e.g. XHR, fetch, script loading, ...).
- Defaults to no limit.
-
---log-level The log level: debug, info, warn, error or fatal.
- Defaults towarn.
-
---log-format The log format: pretty or logfmt.
- Defaults to logfmt.
-
---log-filter-scopes
- Filter out too verbose logs per scope:
- http, unknown_prop, event, ...
-
---user-agent-suffix
- Suffix to append to the Lightpanda/X.Y User-Agent
-
---web-bot-auth-key-file
- Path to the Ed25519 private key PEM file.
-
---web-bot-auth-keyid
- The JWK thumbprint of your public key.
-
---web-bot-auth-domain
- Your domain e.g. yourdomain.com
-```
-
-See also [how to configure proxy](/open-source/guides/configure-a-proxy).
-
-## CDP server
-
-To control Lightpanda with [Chrome Devtool Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP) clients like [Playwright](https://playwright.dev/) or [Puppeteer](https://pptr.dev/), you
-need to start the browser as a CDP server.
-
-```sh copy
-./lightpanda serve --obey-robots --host 127.0.0.1 --port 9222
-```
-```sh
-INFO app : server running . . . . . . . . . . . . . . . . . [+0ms]
- address = 127.0.0.1:9222
-```
-### `serve` command options
-
-```bash
---host Host of the CDP server
- Defaults to "127.0.0.1"
-
---port Port of the CDP server
- Defaults to 9222
-
---advertise-host
- The host to advertise, e.g. in the /json/version response.
- Useful, for example, when --host is 0.0.0.0.
- Defaults to --host value
-
---cdp-max-connections
- Maximum number of simultaneous CDP connections.
- Defaults to 16.
-
---cdp-max-pending-connections
- Maximum pending connections in the accept queue.
- Defaults to 128.
-
---insecure-disable-tls-host-verification
- Disables host verification on all HTTP requests. This is an
- advanced option which should only be set if you understand
- and accept the risk of disabling host verification.
-
---obey-robots
- Fetches and obeys the robots.txt (if available) of the web pages
- we make requests towards.
- Defaults to false.
-
---http-proxy The HTTP proxy to use for all HTTP requests.
- A username:password can be included for basic authentication.
- Defaults to none.
-
---proxy-bearer-token
- The to send for bearer authentication with the proxy
- Proxy-Authorization: Bearer
-
---http-max-concurrent
- The maximum number of concurrent HTTP requests.
- Defaults to 10.
-
---http-max-host-open
- The maximum number of open connection to a given host:port.
- Defaults to 4.
-
---http-connect-timeout
- The time, in milliseconds, for establishing an HTTP connection
- before timing out. 0 means it never times out.
- Defaults to 0.
-
---http-timeout
- The maximum time, in milliseconds, the transfer is allowed
- to complete. 0 means it never times out.
- Defaults to 10000.
-
---http-max-response-size
- Limits the acceptable response size for any request
- (e.g. XHR, fetch, script loading, ...).
- Defaults to no limit.
-
---log-level The log level: debug, info, warn, error or fatal.
- Defaults towarn.
-
---log-format The log format: pretty or logfmt.
- Defaults to logfmt.
-
---log-filter-scopes
- Filter out too verbose logs per scope:
- http, unknown_prop, event, ...
-
---user-agent-suffix
- Suffix to append to the Lightpanda/X.Y User-Agent
-
---web-bot-auth-key-file
- Path to the Ed25519 private key PEM file.
-
---web-bot-auth-keyid
- The JWK thumbprint of your public key.
-
---web-bot-auth-domain
- Your domain e.g. yourdomain.com
-```
-
-See also [how to configure proxy](/open-source/guides/configure-a-proxy).
-
-### Connect with Puppeteer
-
-Once the CDP server started, you can run a [Puppeteer](https://playwright.dev/)
-script by configuring the `browserWSEndpoint`.
-
-```js copy
-'use strict'
-
-import puppeteer from 'puppeteer-core'
-
-// use browserWSEndpoint to pass the Lightpanda's CDP server address.
-const browser = await puppeteer.connect({
- browserWSEndpoint: "ws://127.0.0.1:9222",
-})
-
-// The rest of your script remains the same.
-const context = await browser.createBrowserContext()
-const page = await context.newPage()
-
-// Dump all the links from the page.
-await page.goto('https://wikipedia.com/')
-
-const links = await page.evaluate(() => {
- return Array.from(document.querySelectorAll('a')).map(row => {
- return row.getAttribute('href')
- })
-})
-
-console.log(links)
-
-await page.close()
-await context.close()
-await browser.disconnect()
-```
-
-### Connect with Playwright
-
-Try Lightpanda with [Playwright](https://playwright.dev/) by using
-`chromium.connectOverCDP` to connect.
-
-```js copy
-import { chromium } from 'playwright-core';
-
-// use connectOverCDP to pass the Lightpanda's CDP server address.
-const browser = await chromium.connectOverCDP('ws://127.0.0.1:9222');
-
-// The rest of your script remains the same.
-const context = await browser.newContext({});
-const page = await context.newPage();
-
-await page.goto('https://wikipedia.com/');
-
-const title = await page.locator('h1').textContent();
-console.log(title);
-
-await page.close();
-await context.close();
-await browser.close();
-```
-
-### Connect with Chromedp
-
-Use Lightpanda with [Chromedp](https://github.com/chromedp/chromedp), a Golang
-client for CDP servers.
-
-```go copy
-package main
-
-import (
- "context"
- "flag"
- "log"
-
- "github.com/chromedp/chromedp"
-)
-
-func main() {
- ctx, cancel = chromedp.NewRemoteAllocator(ctx,
- "ws://127.0.0.1:9222", chromedp.NoModifyURL,
- )
- defer cancel()
-
- ctx, cancel := chromedp.NewContext(allocatorContext)
- defer cancel()
-
- var title string
- if err := chromedp.Run(ctx,
- chromedp.Navigate("https://wikipedia.com/"),
- chromedp.Title(&title),
- ); err != nil {
- log.Fatalf("Failed getting page's title: %v", err)
- }
-
- log.Println("Got title of:", title)
-}
-```
-
-## MCP server
-
-Starts an MCP (Model Context Protocol) server over stdio
-
-
-```sh copy
-./lightpanda mcp
-```
-
-### Tools
-
-| Name | Description |
-|-|-|
-| goto | Navigate to a specified URL and load the page in memory so it can be reused later for info extraction |
-| markdown | Get the page content in markdown format. If a url is provided, it navigates to that url first. |
-| links | Extract all links in the opened page. If a url is provided, it navigates to that url first. |
-| evaluate | Evaluate JavaScript in the current page context. If a url is provided, it navigates to that url first. |
-| semantic_tree | Get the page content as a simplified semantic DOM tree for AI reasoning. If a url is provided, it navigates to that url first. |
-| interactiveElements | Extract interactive elements from the opened page. If a url is provided, it navigates to that url first. |
-| structuredData | Extract structured data (like JSON-LD, OpenGraph, etc) from the opened page. If a url is provided, it navigates to that url first. |
-| detectForms | Detect all forms on the page and return their structure including fields, types, and required status. If a url is provided, it navigates to that url first. |
-| click | Click on an interactive element. Returns the current page URL and title after the click. |
-| fill | Fill text into an input element. Returns the filled value and current page URL and title. |
-| scroll | Scroll the page or a specific element. Returns the scroll position and current page URL and title. |
-| waitForSelector | Wait for an element matching a CSS selector to appear in the page. Returns the backend node ID of the matched element. |
-
-### Options
-
-```bash
---insecure-disable-tls-host-verification
- Disables host verification on all HTTP requests. This is an
- advanced option which should only be set if you understand
- and accept the risk of disabling host verification.
-
---obey-robots
- Fetches and obeys the robots.txt (if available) of the web pages
- we make requests towards.
- Defaults to false.
-
---http-proxy The HTTP proxy to use for all HTTP requests.
- A username:password can be included for basic authentication.
- Defaults to none.
-
---proxy-bearer-token
- The to send for bearer authentication with the proxy
- Proxy-Authorization: Bearer
-
---http-max-concurrent
- The maximum number of concurrent HTTP requests.
- Defaults to 10.
-
---http-max-host-open
- The maximum number of open connection to a given host:port.
- Defaults to 4.
-
---http-connect-timeout
- The time, in milliseconds, for establishing an HTTP connection
- before timing out. 0 means it never times out.
- Defaults to 0.
-
---http-timeout
- The maximum time, in milliseconds, the transfer is allowed
- to complete. 0 means it never times out.
- Defaults to 10000.
-
---http-max-response-size
- Limits the acceptable response size for any request
- (e.g. XHR, fetch, script loading, ...).
- Defaults to no limit.
-
---log-level The log level: debug, info, warn, error or fatal.
- Defaults towarn.
-
---log-format The log format: pretty or logfmt.
- Defaults to logfmt.
-
---log-filter-scopes
- Filter out too verbose logs per scope:
- http, unknown_prop, event, ...
-
---user-agent-suffix
- Suffix to append to the Lightpanda/X.Y User-Agent
-
---web-bot-auth-key-file
- Path to the Ed25519 private key PEM file.
-
---web-bot-auth-keyid
- The JWK thumbprint of your public key.
-
---web-bot-auth-domain
- Your domain e.g. yourdomain.com
-```
-
-### Claude Desktop / Cursor / Windsurf
-
-Add to your MCP host configuration:
-
-- **Claude Desktop:** Settings > Developer > Edit Config
-- **Cursor:** `.cursor/mcp.json` in your project
-- **Windsurf:** Cascade MCP settings
-
-```json copy
-{
- "mcpServers": {
- "lightpanda": {
- "command": "/path/to/lightpanda",
- "args": ["mcp"]
- }
- }
-}
-```
diff --git a/src/content/quickstart.mdx b/src/content/quickstart.mdx
new file mode 100644
index 0000000..cc6552b
--- /dev/null
+++ b/src/content/quickstart.mdx
@@ -0,0 +1,894 @@
+---
+title: Quickstart
+description: Set up your first project with Lightpanda browser and run it locally in under 10 minutes.
+---
+import { FileTree } from 'nextra/components'
+import { Tabs } from 'nextra/components'
+import { Callout } from 'nextra/components'
+
+# Quickstart
+
+In this Quickstart, you'll set up your first project with [Lightpanda browser](https://lightpanda.io) and run it locally in under 10 minutes.
+By the end of this guide, you'll have:
+* A working [Node.js](https://nodejs.org) project configured with Lightpanda
+* A browser instance that starts and stops programmatically
+* The foundation for running automated scripts using either [Puppeteer](https://pptr.dev) or [Playwright](https://playwright.dev/) to control the browser
+
+## 1. Installation and setup
+
+### Prerequisites
+
+You'll need [Node.js](https://nodejs.org/en/download) installed on your computer.
+
+### Initialize the Node.js project
+
+Create a `hn-scraper` directory and initialize a new Node.js project.
+
+```sh copy
+mkdir hn-scraper && \
+ cd hn-scraper && \
+ npm init
+```
+
+You can accept all the default values in the npm init prompts. When done, your
+directory should look like this:
+
+
+
+
+
+
+
+
+### Install Lightpanda dependency
+
+Install Lightpanda by using the [official npm package](https://www.npmjs.com/package/@lightpanda/browser).
+
+
+
+ ```sh copy
+ npm install --save @lightpanda/browser
+ ```
+
+
+ ```sh copy
+ yarn add @lightpanda/browser
+ ```
+
+
+ ```sh copy
+ pnpm add @lightpanda/browser
+ ```
+
+
+
+Create an `index.js` file with the following content:
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Do your magic ✨
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+Run your script to start and stop a Lightpanda browser.
+
+```sh copy
+node index.js
+```
+Starting and stopping the browser is almost instant.
+```sh
+$ node index.js
+🐼 Running Lightpanda's CDP server... { pid: 4084512 }
+```
+
+## 2. Your first test
+
+Lightpanda is a headless browser built from scratch. Unlike Headless Chrome, it
+has no UI or graphical rendering for humans, which allows it to start instantly
+and execute pages up to 10x faster.
+
+Unlike [curl](https://curl.se/), which only fetches raw HTML, Lightpanda can
+execute JavaScript and run query selectors directly in the browser.
+
+It's ideal for crawling, testing, and running AI agents that need to interact
+with dynamic web pages, and it's fully compatible with libraries like
+[Puppeteer](https://pptr.dev/) and [Playwright](https://playwright.dev/).
+
+In this example, you'll connect CDP client, [Puppeteer](https://pptr.dev/) or [Playwright](https://playwright.dev/) to Lightpanda
+and extract all reference links from a [Wikipedia
+page](https://www.wikipedia.org/).
+
+### Connect CDP Client to Lightpanda
+
+Install the [`puppeteer-core`](https://www.npmjs.com/package/puppeteer-core) *or* [`playwright-core`](https://www.npmjs.com/package/playwright-core) npm package.
+
+
+ Unlike `puppeteer` and `playwright` npm packages,
+ `puppeteer-core` and `playwright-core` don't download a Chromium browser.
+
+
+
+
+```sh copy
+npm install -save puppeteer-core
+```
+
+
+```sh copy
+npm install -save playwright-core
+```
+
+
+
+Edit your `index.js` to connect to Lightpanda:
+
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import puppeteer from 'puppeteer-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const puppeteeropts = {
+ browserWSEndpoint: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect Puppeteer to the browser.
+ const browser = await puppeteer.connect(puppeteeropts);
+ const context = await browser.createBrowserContext();
+ const page = await context.newPage();
+
+ // Do your magic ✨
+ console.log("CDP connection is working");
+
+ // Disconnect Puppeteer.
+ await page.close();
+ await context.close();
+ await browser.disconnect();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import { chromium } from 'playwright-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const playwrightopts = {
+ endpointURL: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect Playwright's chromium driver to the browser.
+ const browser = await chromium.connectOverCDP(playwrightopts);
+ const context = await browser.newContext({});
+ const page = await context.newPage();
+
+ // Do your magic ✨
+ console.log("CDP connection is working");
+
+ // Disconnect Puppeteer.
+ await page.close();
+ await context.close();
+ await browser.close();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+
+Run the script to test the connection between Puppeteer or Playwright and Lightpanda:
+
+```sh copy
+node index.js
+```
+```sh
+$ node index.js
+🐼 Running Lightpanda's CDP server... { pid: 31371 }
+CDP connection is working
+```
+
+### Extract all reference links from Wikipedia
+
+Update `index.js` using `page.goto` to navigate to a Wikipedia page and extract
+all the reference links:
+
+
+
+```javascript copy
+ // Go to Wikipedia page.
+ await page.goto("https://en.wikipedia.org/wiki/Web_browser");
+```
+
+
+```javascript copy
+ // Go to Wikipedia page.
+ await page.goto("https://en.wikipedia.org/wiki/Web_browser");
+```
+
+
+
+Execute a query selector on the browser to extract the links:
+
+
+
+```javascript copy
+ // Extract all links from the references list of the page.
+ const reflist = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.references a.external')).map(row => {
+ return row.getAttribute('href');
+ });
+ });
+```
+
+
+```javascript copy
+ // Extract all links from the references list of the page.
+ const reflist = await page.locator('.references a.external').evaluateAll(links =>
+ links.map(link => link.getAttribute('href'))
+ );
+```
+
+
+
+Here's the full `index.js` file:
+
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import puppeteer from 'puppeteer-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const puppeteeropts = {
+ browserWSEndpoint: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect Puppeteer to the browser.
+ const browser = await puppeteer.connect(puppeteeropts);
+ const context = await browser.createBrowserContext();
+ const page = await context.newPage();
+
+ // Go to Wikipedia page.
+ await page.goto("https://en.wikipedia.org/wiki/Web_browser");
+
+ // Extract all links from the references list of the page.
+ const reflist = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.references a.external')).map(row => {
+ return row.getAttribute('href');
+ });
+ });
+
+ // Display the result.
+ console.log("all reference links", reflist);
+
+ // Disconnect Puppeteer.
+ await page.close();
+ await context.close();
+ await browser.disconnect();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import { chromium } from 'playwright-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const playwrightopts = {
+ endpointURL: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect using Playwright's chromium driver to the browser.
+ const browser = await chromium.connectOverCDP(playwrightopts);
+ const context = await browser.newContext({});
+ const page = await context.newPage();
+
+ // Go to Wikipedia page.
+ await page.goto("https://en.wikipedia.org/wiki/Web_browser");
+
+ // Extract all links from the references list of the page.
+ const reflist = await page.locator('.references a.external').evaluateAll(links =>
+ links.map(link => link.getAttribute('href'))
+ );
+
+ // Display the result.
+ console.log("all reference links", reflist);
+
+ // Disconnect Playwright.
+ await page.close();
+ await context.close();
+ await browser.close();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+
+### Execute the link extraction
+
+Execute index.js to see the links directly in your console:
+```sh copy
+node index.js
+```
+
+```sh
+$ node index.js
+🐼 Running Lightpanda's CDP server... { pid: 34389 }
+all reference links [
+ 'https://gs.statcounter.com/browser-market-share',
+ 'https://radar.cloudflare.com/reports/browser-market-share-2024-q1',
+ 'https://web.archive.org/web/20240523140912/https://www.internetworldstats.com/stats.htm',
+ 'https://www.internetworldstats.com/stats.htm',
+ 'https://www.reference.com/humanities-culture/purpose-browser-e61874e41999ede',
+```
+
+## 3. Extract data
+
+We will now use the browser to run a search on the [HackerNews
+website](https://news.ycombinator.com/). We need Lightpanda here because the
+website uses XHR requests to display search results. We will also run query
+selectors directly in the browser to extract
+and structure the data.
+
+
+
+### Navigate and search
+
+Similar to the Wikipedia example, edit `index.js` to navigate to HackerNews:
+
+
+
+```javascript copy
+ await page.goto("https://news.ycombinator.com/");
+```
+
+
+```javascript copy
+ await page.goto("https://news.ycombinator.com/");
+```
+
+
+
+Type the term lightpanda in the search input at the bottom of the page and
+press the Enter key to submit the search:
+
+
+
+```javascript copy
+ await page.type('input[name="q"]','lightpanda');
+ await page.keyboard.press('Enter');
+```
+
+
+```javascript copy
+ await page.locator('input[name="q"]').fill('lightpanda');
+ await page.keyboard.press('Enter');
+```
+
+
+
+Wait for the search results to be displayed, with a timeout limit of 5 seconds:
+
+
+
+```javascript copy
+ await page.waitForFunction(() => {
+ return document.querySelector('.Story_container') != null;
+ }, {timeout: 5000});
+```
+
+
+```javascript copy
+ await page.waitForSelector('.Story_container', { timeout: 5000 });
+```
+
+
+
+### Extract the data
+
+We will loop over the search results to extract the title, the URL, and a list
+of metadata including the author, the number of points, and comments:
+
+
+
+```javascript copy
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+```
+
+
+```javascript copy
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+```
+
+
+
+### The final script
+
+Here is the full version of index.js updated to run the search and extract
+results:
+
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import puppeteer from 'puppeteer-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const puppeteeropts = {
+ browserWSEndpoint: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect Puppeteer to the browser.
+ const browser = await puppeteer.connect(puppeteeropts);
+ const context = await browser.createBrowserContext();
+ const page = await context.newPage();
+
+ // Go to hackernews home page.
+ await page.goto("https://news.ycombinator.com/");
+
+ // Find the search box at the bottom of the page and type the term lightpanda
+ // to search.
+ await page.type('input[name="q"]','lightpanda');
+ // Press enter key to run the search.
+ await page.keyboard.press('Enter');
+
+ // Wait until the search results are loaded on the page, with a 5 seconds
+ // timeout limit.
+ await page.waitForFunction(() => {
+ return document.querySelector('.Story_container') != null;
+ }, {timeout: 5000});
+
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+
+ // Display the result.
+ console.log(res);
+
+ // Disconnect Puppeteer.
+ await page.close();
+ await context.close();
+ await browser.disconnect();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+```javascript copy
+'use strict'
+
+import { lightpanda } from '@lightpanda/browser';
+import { chromium } from 'playwright-core';
+
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+
+const playwrightopts = {
+ endpointURL: 'ws://' + lpdopts.host + ':' + lpdopts.port,
+};
+
+(async () => {
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+
+ // Connect using Playwright's chromium driver to the browser.
+ const browser = await chromium.connectOverCDP(playwrightopts);
+ const context = await browser.newContext({});
+ const page = await context.newPage();
+
+ // Go to hackernews home page.
+ await page.goto("https://news.ycombinator.com/");
+
+ // Find the search box at the bottom of the page and type the term lightpanda
+ // to search.
+ await page.locator('input[name="q"]').fill('lightpanda');
+ // Press enter key to run the search.
+ await page.keyboard.press('Enter');
+
+ // Wait until the search results are loaded on the page, with a 5 seconds
+ // timeout limit.
+ await page.waitForSelector('.Story_container', { timeout: 5000 });
+
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+
+ // Display the result.
+ console.log(res);
+
+ // Disconnect Playwright.
+ await page.close();
+ await context.close();
+ await browser.close();
+
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+})();
+```
+
+
+
+### Run the script
+
+You can run it to see the result immediately:
+
+```sh copy
+node index.js
+```
+```sh
+$ node index.js
+🐼 Running Lightpanda's CDP server… { pid: 598201 }
+[
+ {
+ title: 'Show HN: Lightpanda, an open-source headless browser in Zig',
+ url: 'https://news.ycombinator.com/item?id=42817439',
+ meta: [ '319 points', 'fbouvier', '9 months ago', '137 comments' ]
+ },
+ {
+ title: 'Lightpanda: Headless browser designed for AI and automation',
+ url: 'https://news.ycombinator.com/item?id=42812859',
+ meta: [ '154 points', 'tosh', '9 months ago', '1 comments' ]
+ },
+ {
+ title: 'Show HN: Lightpanda, an open-source headless browser in Zig',
+ url: 'https://news.ycombinator.com/item?id=42430629',
+ meta: [ '7 points', 'fbouvier', '10 months ago', '0 comments' ]
+ },
+ {
+ title: 'Lightpanda: Fast headless browser from scratch in Zig for AI and automation',
+ url: 'https://news.ycombinator.com/item?id=44900394',
+ meta: [ '5 points', 'lioeters', '2 months ago', '0 comments' ]
+ },
+ {
+ title: 'Lightpanda – The Headless Browser',
+ url: 'https://news.ycombinator.com/item?id=42745150',
+ meta: [ '4 points', 'vladkens', '9 months ago', '2 comments' ]
+ },
+ {
+ title: 'Lightpanda raises pre-seed to develop first browser built for machines and AI',
+ url: 'https://news.ycombinator.com/item?id=44263271',
+ meta: [ '1 points', 'cpeterso', '4 months ago', '0 comments' ]
+ }
+]
+```
+
+## 4. Go to production
+
+Use [Lightpanda's cloud offer](https://lightpanda.io/#cloud-offer) to switch from
+a local browser to a remotely managed version.
+
+Create a new account and an API token [here](https://console.lightpanda.io/signup).
+
+To connect, the script will use an environment variable named `LPD_TOKEN`.
+First export the variable with your token.
+
+```sh copy
+export LPD_TOKEN="paste your token here"
+```
+
+Edit `index.js` to change the Puppeteer connection options:
+
+
+
+```javascript copy
+const puppeteeropts = {
+ browserWSEndpoint: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
+};
+```
+
+
+```javascript copy
+const playwrightopts = {
+ endpointURL: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
+};
+```
+
+
+
+
+Depending on your location, you can connect using the url
+`wss://euwest.cloud.lightpanda.io/ws` or `wss//uswest.cloud.lightpanda.io/ws`.
+
+
+### Clean up local-only lines
+
+You no longer need to start a local browser process because you are using the
+cloud version. You can remove these parts of the script to simplify it:
+
+```javascript
+import { lightpanda } from '@lightpanda/browser';
+```
+```javascript
+const lpdopts = {
+ host: '127.0.0.1',
+ port: 9222,
+};
+```
+```javascript
+ // Start Lightpanda browser in a separate process.
+ const proc = await lightpanda.serve(lpdopts);
+```
+```javascript
+ // Stop Lightpanda browser process.
+ proc.stdout.destroy();
+ proc.stderr.destroy();
+ proc.kill();
+```
+
+### Final version
+
+Here is the final script using the cloud browser version:
+
+
+
+```javascript copy
+'use strict'
+
+import puppeteer from 'puppeteer-core';
+
+const puppeteeropts = {
+ browserWSEndpoint: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
+};
+
+(async () => {
+ // Connect Puppeteer to the browser.
+ const browser = await puppeteer.connect(puppeteeropts);
+ const context = await browser.createBrowserContext();
+ const page = await context.newPage();
+
+ // Go to hackernews home page.
+ await page.goto("https://news.ycombinator.com/");
+
+ // Find the search box at the bottom of the page and type the term lightpanda
+ // to search.
+ await page.type('input[name="q"]','lightpanda');
+ // Press enter key to run the search.
+ await page.keyboard.press('Enter');
+
+ // Wait until the search results are loaded on the page, with a 5 seconds
+ // timeout limit.
+ await page.waitForFunction(() => {
+ return document.querySelector('.Story_container') != null;
+ }, {timeout: 5000});
+
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+
+ // Display the result.
+ console.log(res);
+
+ // Disconnect Puppeteer.
+ await page.close();
+ await context.close();
+ await browser.disconnect();
+})();
+```
+
+
+```javascript copy
+'use strict'
+
+import { chromium } from 'playwright-core';
+
+const playwrightopts = {
+ endpointURL: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
+};
+
+(async () => {
+ // Connect using Playwright's chromium driver to the browser.
+ const browser = await chromium.connectOverCDP(playwrightopts);
+ const context = await browser.newContext({});
+ const page = await context.newPage();
+
+ // Go to hackernews home page.
+ await page.goto("https://news.ycombinator.com/");
+
+ // Find the search box at the bottom of the page and type the term lightpanda
+ // to search.
+ await page.locator('input[name="q"]').fill('lightpanda');
+ // Press enter key to run the search.
+ await page.keyboard.press('Enter');
+
+ // Wait until the search results are loaded on the page, with a 5 seconds
+ // timeout limit.
+ await page.waitForSelector('.Story_container', { timeout: 5000 });
+
+ // Loop over search results to extract data.
+ const res = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('.Story_container')).map(row => {
+ return {
+ // Extract the title.
+ title: row.querySelector('.Story_title span').textContent,
+ // Extract the URL.
+ url: row.querySelector('.Story_title a').getAttribute('href'),
+ // Extract the list of meta data.
+ meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
+ return row.textContent;
+ }),
+ }
+ });
+ });
+
+ // Display the result.
+ console.log(res);
+
+ // Disconnect Playwright.
+ await page.close();
+ await context.close();
+ await browser.close();
+})();
+```
+
+
+
+### Interested in on premise deployment?
+
+The core Lightpanda browser will always remain open source, including
+JavaScript execution, CDP compatibility, proxy support, and request
+interception.
+
+If you require on premise deployment, proprietary licensing, or enterprise
+features such as multi-context tabs and sandboxing, reach out to us at
+[hello@lightpanda.io](mailto:hello@lightpanda.io).
+
+### Need help?
+
+Stuck or have questions about your use case? Open an issue on GitHub or [join our Discord](https://discord.com/invite/K63XeymfB5).
diff --git a/src/content/quickstart/_meta.ts b/src/content/quickstart/_meta.ts
deleted file mode 100644
index 2857955..0000000
--- a/src/content/quickstart/_meta.ts
+++ /dev/null
@@ -1,10 +0,0 @@
-import type { MetaRecord } from 'nextra'
-
-const meta: MetaRecord = {
- 'installation-and-setup': '1. Installation and setup',
- 'your-first-test': '2. Your first test',
- 'build-your-first-extraction-script': '3. Extract data',
- 'go-to-production-with-lightpanda-cloud': '4. Go to production',
-}
-
-export default meta
diff --git a/src/content/quickstart/go-to-production-with-lightpanda-cloud.mdx b/src/content/quickstart/go-to-production-with-lightpanda-cloud.mdx
deleted file mode 100644
index e64c829..0000000
--- a/src/content/quickstart/go-to-production-with-lightpanda-cloud.mdx
+++ /dev/null
@@ -1,202 +0,0 @@
----
-title: Go to production with Lightpanda cloud
-description: Learn how to use a remote Lightpanda browser
----
-import { Callout } from 'nextra/components'
-import { Tabs } from 'nextra/components'
-
-# 4. Go to production
-
-Use [Lightpanda's cloud offer](https://lightpanda.io/#cloud-offer) to switch from
-a local browser to a remotely managed version.
-
-Create a new account and an API token [here](https://console.lightpanda.io/signup).
-
-To connect, the script will use an environment variable named `LPD_TOKEN`.
-First export the variable with your token.
-
-```sh copy
-export LPD_TOKEN="paste your token here"
-```
-
-Edit `index.js` to change the Puppeteer connection options:
-
-
-
-```javascript copy
-const puppeteeropts = {
- browserWSEndpoint: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
-};
-```
-
-
-```javascript copy
-const playwrightopts = {
- endpointURL: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
-};
-```
-
-
-
-
-Depending on your location, you can connect using the url
-`wss://euwest.cloud.lightpanda.io/ws` or `wss//uswest.cloud.lightpanda.io/ws`.
-
-
-## Clean up local-only lines
-
-You no longer need to start a local browser process because you are using the
-cloud version. You can remove these parts of the script to simplify it:
-
-```javascript
-import { lightpanda } from '@lightpanda/browser';
-```
-```javascript
-const lpdopts = {
- host: '127.0.0.1',
- port: 9222,
-};
-```
-```javascript
- // Start Lightpanda browser in a separate process.
- const proc = await lightpanda.serve(lpdopts);
-```
-```javascript
- // Stop Lightpanda browser process.
- proc.stdout.destroy();
- proc.stderr.destroy();
- proc.kill();
-```
-
-## Final version
-
-Here is the final script using the cloud browser version:
-
-
-
-```javascript copy
-'use strict'
-
-import puppeteer from 'puppeteer-core';
-
-const puppeteeropts = {
- browserWSEndpoint: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
-};
-
-(async () => {
- // Connect Puppeteer to the browser.
- const browser = await puppeteer.connect(puppeteeropts);
- const context = await browser.createBrowserContext();
- const page = await context.newPage();
-
- // Go to hackernews home page.
- await page.goto("https://news.ycombinator.com/");
-
- // Find the search box at the bottom of the page and type the term lightpanda
- // to search.
- await page.type('input[name="q"]','lightpanda');
- // Press enter key to run the search.
- await page.keyboard.press('Enter');
-
- // Wait until the search results are loaded on the page, with a 5 seconds
- // timeout limit.
- await page.waitForFunction(() => {
- return document.querySelector('.Story_container') != null;
- }, {timeout: 5000});
-
- // Loop over search results to extract data.
- const res = await page.evaluate(() => {
- return Array.from(document.querySelectorAll('.Story_container')).map(row => {
- return {
- // Extract the title.
- title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
- url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
- meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
- return row.textContent;
- }),
- }
- });
- });
-
- // Display the result.
- console.log(res);
-
- // Disconnect Puppeteer.
- await page.close();
- await context.close();
- await browser.disconnect();
-})();
-```
-
-
-```javascript copy
-'use strict'
-
-import { chromium } from 'playwright-core';
-
-const playwrightopts = {
- endpointURL: 'wss://euwest.cloud.lightpanda.io/ws?token=' + process.env.LPD_TOKEN,
-};
-
-(async () => {
- // Connect using Playwright's chromium driver to the browser.
- const browser = await chromium.connectOverCDP(playwrightopts);
- const context = await browser.newContext({});
- const page = await context.newPage();
-
- // Go to hackernews home page.
- await page.goto("https://news.ycombinator.com/");
-
- // Find the search box at the bottom of the page and type the term lightpanda
- // to search.
- await page.locator('input[name="q"]').fill('lightpanda');
- // Press enter key to run the search.
- await page.keyboard.press('Enter');
-
- // Wait until the search results are loaded on the page, with a 5 seconds
- // timeout limit.
- await page.waitForSelector('.Story_container', { timeout: 5000 });
-
- // Loop over search results to extract data.
- const res = await page.evaluate(() => {
- return Array.from(document.querySelectorAll('.Story_container')).map(row => {
- return {
- // Extract the title.
- title: row.querySelector('.Story_title span').textContent,
- // Extract the URL.
- url: row.querySelector('.Story_title a').getAttribute('href'),
- // Extract the list of meta data.
- meta: Array.from(row.querySelectorAll('.Story_meta > span:not(.Story_separator, .Story_comment)')).map(row => {
- return row.textContent;
- }),
- }
- });
- });
-
- // Display the result.
- console.log(res);
-
- // Disconnect Playwright.
- await page.close();
- await context.close();
- await browser.close();
-})();
-```
-
-
-
-## Interested in on premise deployment?
-
-The core Lightpanda browser will always remain open source, including
-JavaScript execution, CDP compatibility, proxy support, and request
-interception.
-
-If you require on premise deployment, proprietary licensing, or enterprise
-features such as multi-context tabs and sandboxing, reach out to us at
-[hello@lightpanda.io](mailto:hello@lightpanda.io).
-
-## Need help?
-
-Stuck or have questions about your use case? Open an issue on GitHub or [join our Discord](https://discord.com/invite/K63XeymfB5).
diff --git a/src/content/quickstart/installation-and-setup.mdx b/src/content/quickstart/installation-and-setup.mdx
deleted file mode 100644
index 07a6c74..0000000
--- a/src/content/quickstart/installation-and-setup.mdx
+++ /dev/null
@@ -1,105 +0,0 @@
----
-title: Installation and setup
-description: Learn how to initialize a Node.js project using Lightpanda browser.
----
-import { FileTree } from 'nextra/components'
-import { Tabs } from 'nextra/components'
-
-# Quickstart
-
-In this Quickstart, you’ll set up your first project with [Lightpanda browser](https://lightpanda.io) and run it locally in under 10 minutes.
-By the end of this guide, you’ll have:
-* A working [Node.js](https://nodejs.org) project configured with Lightpanda
-* A browser instance that starts and stops programmatically
-* The foundation for running automated scripts using either [Puppeteer](https://pptr.dev) or [Playwright](https://playwright.dev/) to control the browser
-
-1. [Installation and setup](/quickstart/installation-and-setup)
-2. [Your first test](/quickstart/your-first-test)
-3. [Extract data](/quickstart/build-your-first-extraction-script)
-4. [Go to production with Lightpanda cloud](/quickstart/go-to-production-with-lightpanda-cloud)
-
-# 1. Installation and setup
-
-## Prerequisites
-
-You'll need [Node.js](https://nodejs.org/en/download) installed on your computer.
-
-## Initialize the Node.js project
-
-Create a `hn-scraper` directory and initialize a new Node.js project.
-
-```sh copy
-mkdir hn-scraper && \
- cd hn-scraper && \
- npm init
-```
-
-You can accept all the default values in the npm init prompts. When done, your
-directory should look like this:
-
-
-
-
-
-
-
-
-## Install Lightpanda dependency
-
-Install Lightpanda by using the [official npm package](https://www.npmjs.com/package/@lightpanda/browser).
-
-
-
- ```sh copy
- npm install --save @lightpanda/browser
- ```
-
-
- ```sh copy
- yarn add @lightpanda/browser
- ```
-
-
- ```sh copy
- pnpm add @lightpanda/browser
- ```
-
-
-
-Create an `index.js` file with the following content:
-
-```javascript copy
-'use strict'
-
-import { lightpanda } from '@lightpanda/browser';
-
-const lpdopts = {
- host: '127.0.0.1',
- port: 9222,
-};
-
-(async () => {
- // Start Lightpanda browser in a separate process.
- const proc = await lightpanda.serve(lpdopts);
-
- // Do your magic ✨
-
- // Stop Lightpanda browser process.
- proc.stdout.destroy();
- proc.stderr.destroy();
- proc.kill();
-})();
-```
-
-Run your script to start and stop a Lightpanda browser.
-
-```sh copy
-node index.js
-```
-Starting and stopping the browser is almost instant.
-```sh
-$ node index.js
-🐼 Running Lightpanda's CDP server... { pid: 4084512 }
-```
-
-### Step 2: [ Your first test](/quickstart/your-first-test)
diff --git a/src/content/run-locally/_meta.ts b/src/content/run-locally/_meta.ts
new file mode 100644
index 0000000..574646c
--- /dev/null
+++ b/src/content/run-locally/_meta.ts
@@ -0,0 +1,19 @@
+import type { MetaRecord } from 'nextra'
+
+const meta: MetaRecord = {
+ installation: {
+ title: 'Installation',
+ theme: {
+ collapsed: false,
+ },
+ },
+ commands: {
+ title: 'Commands',
+ theme: {
+ collapsed: false,
+ },
+ },
+ 'configure-a-proxy': 'Configure a proxy',
+}
+
+export default meta
diff --git a/src/content/open-source/guides/_meta.ts b/src/content/run-locally/commands/_meta.ts
similarity index 50%
rename from src/content/open-source/guides/_meta.ts
rename to src/content/run-locally/commands/_meta.ts
index 5462562..d5fb92b 100644
--- a/src/content/open-source/guides/_meta.ts
+++ b/src/content/run-locally/commands/_meta.ts
@@ -1,8 +1,8 @@
import type { MetaRecord } from 'nextra'
const meta: MetaRecord = {
- 'build-from-sources': 'Build from sources',
- 'configure-a-proxy': 'Configure a proxy',
+ fetch: 'Fetch (+ options)',
+ serve: 'CDP server (+ options)',
}
export default meta
diff --git a/src/content/run-locally/commands/fetch.mdx b/src/content/run-locally/commands/fetch.mdx
new file mode 100644
index 0000000..51e9a4b
--- /dev/null
+++ b/src/content/run-locally/commands/fetch.mdx
@@ -0,0 +1,126 @@
+---
+title: Fetch
+description: Fetch a webpage and dump its content using the Lightpanda CLI.
+---
+
+# Fetch
+
+Use `./lightpanda help` for all options.
+
+```sh copy
+./lightpanda fetch --obey-robots --dump html https://demo-browser.lightpanda.io/campfire-commerce/
+```
+```sh
+INFO http : navigate . . . . . . . . . . . . . . . . . . . . [+0ms]
+ url = https://demo-browser.lightpanda.io/campfire-commerce/
+ method = GET
+ reason = address_bar
+ body = false
+
+INFO browser : executing script . . . . . . . . . . . . . . [+196ms]
+ src = https://demo-browser.lightpanda.io/campfire-commerce/script.js
+ kind = javascript
+ cacheable = true
+
+INFO http : request complete . . . . . . . . . . . . . . . . [+223ms]
+ source = xhr
+ url = https://demo-browser.lightpanda.io/campfire-commerce/json/product.json
+ status = 200
+
+INFO http : request complete . . . . . . . . . . . . . . . . [+234ms]
+ source = xhr
+ url = https://demo-browser.lightpanda.io/campfire-commerce/json/reviews.json
+ status = 200
+
+```
+
+## Options
+
+```bash
+--dump Dumps document to stdout.
+ Argument must be 'html', 'markdown', 'semantic_tree', or 'semantic_tree_text'.
+ Defaults to no dump.
+
+--strip-mode Comma separated list of tag groups to remove from dump
+ the dump. e.g. --strip-mode js,css
+ - "js" script and link[as=script, rel=preload]
+ - "ui" includes img, picture, video, css and svg
+ - "css" includes style and link[rel=stylesheet]
+ - "full" includes js, ui and css
+
+--with-base Add a tag in dump. Defaults to false.
+
+--with-frames Includes the contents of iframes. Defaults to false.
+
+--wait-ms Wait time in milliseconds.
+ Defaults to 5000.
+
+--wait-until Wait until the specified event.
+ Supported events: load, domcontentloaded, networkidle, done.
+ Defaults to 'done'.
+
+--insecure-disable-tls-host-verification
+ Disables host verification on all HTTP requests. This is an
+ advanced option which should only be set if you understand
+ and accept the risk of disabling host verification.
+
+--obey-robots
+ Fetches and obeys the robots.txt (if available) of the web pages
+ we make requests towards.
+ Defaults to false.
+
+--http-proxy The HTTP proxy to use for all HTTP requests.
+ A username:password can be included for basic authentication.
+ Defaults to none.
+
+--proxy-bearer-token
+ The to send for bearer authentication with the proxy
+ Proxy-Authorization: Bearer
+
+--http-max-concurrent
+ The maximum number of concurrent HTTP requests.
+ Defaults to 10.
+
+--http-max-host-open
+ The maximum number of open connection to a given host:port.
+ Defaults to 4.
+
+--http-connect-timeout
+ The time, in milliseconds, for establishing an HTTP connection
+ before timing out. 0 means it never times out.
+ Defaults to 0.
+
+--http-timeout
+ The maximum time, in milliseconds, the transfer is allowed
+ to complete. 0 means it never times out.
+ Defaults to 10000.
+
+--http-max-response-size
+ Limits the acceptable response size for any request
+ (e.g. XHR, fetch, script loading, ...).
+ Defaults to no limit.
+
+--log-level The log level: debug, info, warn, error or fatal.
+ Defaults towarn.
+
+--log-format The log format: pretty or logfmt.
+ Defaults to logfmt.
+
+--log-filter-scopes
+ Filter out too verbose logs per scope:
+ http, unknown_prop, event, ...
+
+--user-agent-suffix
+ Suffix to append to the Lightpanda/X.Y User-Agent
+
+--web-bot-auth-key-file
+ Path to the Ed25519 private key PEM file.
+
+--web-bot-auth-keyid
+ The JWK thumbprint of your public key.
+
+--web-bot-auth-domain
+ Your domain e.g. yourdomain.com
+```
+
+See also [how to configure proxy](/run-locally/configure-a-proxy).
diff --git a/src/content/run-locally/commands/serve.mdx b/src/content/run-locally/commands/serve.mdx
new file mode 100644
index 0000000..f9d881d
--- /dev/null
+++ b/src/content/run-locally/commands/serve.mdx
@@ -0,0 +1,107 @@
+---
+title: Serve
+description: Start Lightpanda as a local CDP server.
+---
+
+# Serve
+
+Start Lightpanda as a [Chrome DevTools Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP) server to control it with clients like [Puppeteer](https://pptr.dev/), [Playwright](https://playwright.dev/) or [Chromedp](https://github.com/chromedp/chromedp).
+
+```sh copy
+./lightpanda serve --obey-robots --host 127.0.0.1 --port 9222
+```
+```sh
+INFO app : server running . . . . . . . . . . . . . . . . . [+0ms]
+ address = 127.0.0.1:9222
+```
+
+## Options
+
+```bash
+--host Host of the CDP server
+ Defaults to "127.0.0.1"
+
+--port Port of the CDP server
+ Defaults to 9222
+
+--advertise-host
+ The host to advertise, e.g. in the /json/version response.
+ Useful, for example, when --host is 0.0.0.0.
+ Defaults to --host value
+
+--timeout Inactivity timeout in seconds before disconnecting clients
+ Defaults to 10 (seconds). Limited to 604800 (1 week).
+
+--cdp-max-connections
+ Maximum number of simultaneous CDP connections.
+ Defaults to 16.
+
+--cdp-max-pending-connections
+ Maximum pending connections in the accept queue.
+ Defaults to 128.
+
+--insecure-disable-tls-host-verification
+ Disables host verification on all HTTP requests. This is an
+ advanced option which should only be set if you understand
+ and accept the risk of disabling host verification.
+
+--obey-robots
+ Fetches and obeys the robots.txt (if available) of the web pages
+ we make requests towards.
+ Defaults to false.
+
+--http-proxy The HTTP proxy to use for all HTTP requests.
+ A username:password can be included for basic authentication.
+ Defaults to none.
+
+--proxy-bearer-token
+ The to send for bearer authentication with the proxy
+ Proxy-Authorization: Bearer
+
+--http-max-concurrent
+ The maximum number of concurrent HTTP requests.
+ Defaults to 10.
+
+--http-max-host-open
+ The maximum number of open connection to a given host:port.
+ Defaults to 4.
+
+--http-connect-timeout
+ The time, in milliseconds, for establishing an HTTP connection
+ before timing out. 0 means it never times out.
+ Defaults to 0.
+
+--http-timeout
+ The maximum time, in milliseconds, the transfer is allowed
+ to complete. 0 means it never times out.
+ Defaults to 10000.
+
+--http-max-response-size
+ Limits the acceptable response size for any request
+ (e.g. XHR, fetch, script loading, ...).
+ Defaults to no limit.
+
+--log-level The log level: debug, info, warn, error or fatal.
+ Defaults towarn.
+
+--log-format The log format: pretty or logfmt.
+ Defaults to logfmt.
+
+--log-filter-scopes
+ Filter out too verbose logs per scope:
+ http, unknown_prop, event, ...
+
+--user-agent-suffix
+ Suffix to append to the Lightpanda/X.Y User-Agent
+
+--web-bot-auth-key-file
+ Path to the Ed25519 private key PEM file.
+
+--web-bot-auth-keyid
+ The JWK thumbprint of your public key.
+
+--web-bot-auth-domain
+ Your domain e.g. yourdomain.com
+```
+
+See also [how to configure proxy](/run-locally/configure-a-proxy).
diff --git a/src/content/open-source/guides/configure-a-proxy.mdx b/src/content/run-locally/configure-a-proxy.mdx
similarity index 100%
rename from src/content/open-source/guides/configure-a-proxy.mdx
rename to src/content/run-locally/configure-a-proxy.mdx
diff --git a/src/content/run-locally/installation/_meta.ts b/src/content/run-locally/installation/_meta.ts
new file mode 100644
index 0000000..d4a871a
--- /dev/null
+++ b/src/content/run-locally/installation/_meta.ts
@@ -0,0 +1,12 @@
+import type { MetaRecord } from 'nextra'
+
+const meta: MetaRecord = {
+ 'one-liner': 'One-liner',
+ docker: 'Docker',
+ 'package-managers': 'Package manager (npm, brew)',
+ 'nightly-builds': 'Nightly builds',
+ 'system-requirements': 'System requirements',
+ 'build-from-sources': 'Build from sources',
+}
+
+export default meta
diff --git a/src/content/open-source/guides/build-from-sources.mdx b/src/content/run-locally/installation/build-from-sources.mdx
similarity index 100%
rename from src/content/open-source/guides/build-from-sources.mdx
rename to src/content/run-locally/installation/build-from-sources.mdx
diff --git a/src/content/run-locally/installation/docker.mdx b/src/content/run-locally/installation/docker.mdx
new file mode 100644
index 0000000..e63890f
--- /dev/null
+++ b/src/content/run-locally/installation/docker.mdx
@@ -0,0 +1,16 @@
+---
+title: Docker
+description: Install Lightpanda using the official Docker image.
+---
+
+# Docker
+
+Lightpanda provides [official Docker
+images](https://hub.docker.com/r/lightpanda/browser) for both Linux amd64 and
+arm64 architectures.
+
+The following command fetches the Docker image and starts a new container exposing Lightpanda's CDP server on port `9222`.
+
+```sh copy
+docker run -d --name lightpanda -p 127.0.0.1:9222:9222 lightpanda/browser:nightly
+```
diff --git a/src/content/run-locally/installation/nightly-builds.mdx b/src/content/run-locally/installation/nightly-builds.mdx
new file mode 100644
index 0000000..acbee66
--- /dev/null
+++ b/src/content/run-locally/installation/nightly-builds.mdx
@@ -0,0 +1,42 @@
+---
+title: Nightly builds
+description: Install Lightpanda manually from the latest nightly builds.
+---
+
+# Nightly builds
+
+The latest binary can be downloaded from the [nightly
+builds](https://github.com/lightpanda-io/browser/releases/tag/nightly) for
+Linux and MacOS.
+
+### Linux x86_64
+```bash copy
+curl -L -o lightpanda \
+ https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-linux && \
+ chmod a+x ./lightpanda
+```
+
+### Linux aarch64
+```bash copy
+curl -L -o lightpanda \
+ https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-aarch64-linux && \
+ chmod a+x ./lightpanda
+```
+
+### MacOS aarch64
+```sh copy
+curl -L -o lightpanda \
+ https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-aarch64-macos && \
+ chmod a+x ./lightpanda
+```
+
+### MacOS x86_64
+```sh copy
+curl -L -o lightpanda \
+ https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-macos && \
+ chmod a+x ./lightpanda
+```
+
+## Telemetry
+
+By default, Lightpanda collects and sends usage telemetry. This can be disabled by setting an environment variable `LIGHTPANDA_DISABLE_TELEMETRY=true`. You can read Lightpanda's privacy policy at: [https://lightpanda.io/privacy-policy](https://lightpanda.io/privacy-policy).
diff --git a/src/content/run-locally/installation/one-liner.mdx b/src/content/run-locally/installation/one-liner.mdx
new file mode 100644
index 0000000..ced57ea
--- /dev/null
+++ b/src/content/run-locally/installation/one-liner.mdx
@@ -0,0 +1,43 @@
+---
+title: One-liner
+description: Install Lightpanda with a single command on Linux or MacOS.
+---
+import { Callout } from 'nextra/components'
+
+# One-liner
+
+For Linux or MacOSx users, you can install Lightpanda with following command.
+For Windows, take a look at the [dedicated section](#windows--wsl2).
+
+```bash copy
+curl -fsSL https://pkg.lightpanda.io/install.sh | bash
+```
+
+
+`curl`, `jq` and `sha256sum` are required to install Lightpanda with the
+one-liner installer.
+
+
+By default the installer installs the last nightly build.
+But you can pick a specific release:
+
+```bash copy
+curl -fsSL https://pkg.lightpanda.io/install.sh | bash -s "v0.2.5"
+```
+
+## Windows + WSL2
+
+The Lightpanda browser is compatible to run on Windows inside WSL (Windows Subsystem for Linux). If WSL has not been installed before follow these steps (for more information see: [MS Windows install WSL](https://learn.microsoft.com/en-us/windows/wsl/install)).
+Install & open WSL + Ubuntu from an **administrator** shell:
+ 1. `wsl --install`
+ 2. -- restart --
+ 3. `wsl --install -d Ubuntu`
+ 4. `wsl`
+
+Once WSL and a Linux distribution have been installed the browser can be installed in the same way it is installed for Linux.
+Inside WSL install the Lightpanda browser:
+```bash copy
+curl -L -o lightpanda https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-linux && \
+chmod a+x ./lightpanda
+```
+It is recommended to install clients like Puppeteer on the Windows host.
diff --git a/src/content/run-locally/installation/package-managers.mdx b/src/content/run-locally/installation/package-managers.mdx
new file mode 100644
index 0000000..0221a37
--- /dev/null
+++ b/src/content/run-locally/installation/package-managers.mdx
@@ -0,0 +1,30 @@
+---
+title: Package managers
+description: Install Lightpanda using Homebrew, Arch AUR, or Debian/Ubuntu packages.
+---
+
+# Package managers
+
+## Homebrew
+
+Install the last nightly using Homebrew.
+
+```sh copy
+brew install lightpanda-io/browser/lightpanda
+```
+
+## Arch Linux User Repository
+
+```sh copy
+yay -S lightpanda-bin
+```
+
+You can alternatively use the last nightly version with:
+```sh copy
+yay -S lightpanda-nightly-bin
+```
+
+## Debian/Ubuntu
+
+Starting `0.3.0`, a `.deb` is available with each [tagged
+release](https://github.com/lightpanda-io/browser/releases).
diff --git a/src/content/open-source/systems-requirements.mdx b/src/content/run-locally/installation/system-requirements.mdx
similarity index 100%
rename from src/content/open-source/systems-requirements.mdx
rename to src/content/run-locally/installation/system-requirements.mdx
diff --git a/src/content/run-on-lightpanda-cloud/_meta.ts b/src/content/run-on-lightpanda-cloud/_meta.ts
new file mode 100644
index 0000000..b2fcd02
--- /dev/null
+++ b/src/content/run-on-lightpanda-cloud/_meta.ts
@@ -0,0 +1,7 @@
+import type { MetaRecord } from 'nextra'
+
+const meta: MetaRecord = {
+ 'getting-started': 'Getting started',
+}
+
+export default meta
diff --git a/src/content/cloud-offer/getting-started.mdx b/src/content/run-on-lightpanda-cloud/getting-started.mdx
similarity index 100%
rename from src/content/cloud-offer/getting-started.mdx
rename to src/content/run-on-lightpanda-cloud/getting-started.mdx
diff --git a/src/content/cloud-offer/_meta.ts b/src/content/usage/_meta.ts
similarity index 66%
rename from src/content/cloud-offer/_meta.ts
rename to src/content/usage/_meta.ts
index a73c132..16c358f 100644
--- a/src/content/cloud-offer/_meta.ts
+++ b/src/content/usage/_meta.ts
@@ -1,13 +1,14 @@
import type { MetaRecord } from 'nextra'
const meta: MetaRecord = {
- 'getting-started': 'Getting started',
- tools: {
- title: 'Tools',
+ cdp: {
+ title: 'CDP',
theme: {
collapsed: false,
},
},
+ mcp: 'MCP',
+ api: 'HTTP API',
}
export default meta
diff --git a/src/content/cloud-offer/tools/api.mdx b/src/content/usage/api.mdx
similarity index 100%
rename from src/content/cloud-offer/tools/api.mdx
rename to src/content/usage/api.mdx
diff --git a/src/content/usage/cdp/_meta.ts b/src/content/usage/cdp/_meta.ts
new file mode 100644
index 0000000..bb30692
--- /dev/null
+++ b/src/content/usage/cdp/_meta.ts
@@ -0,0 +1,9 @@
+import type { MetaRecord } from 'nextra'
+
+const meta: MetaRecord = {
+ puppeteer: 'Puppeteer',
+ playwright: 'Playwright',
+ chromedp: 'Chromedp',
+}
+
+export default meta
diff --git a/src/content/usage/cdp/chromedp.mdx b/src/content/usage/cdp/chromedp.mdx
new file mode 100644
index 0000000..49b5987
--- /dev/null
+++ b/src/content/usage/cdp/chromedp.mdx
@@ -0,0 +1,121 @@
+---
+title: Chromedp
+description: Use Lightpanda with Chromedp via CDP, locally or on the cloud.
+---
+import { Tabs } from 'nextra/components'
+
+# Chromedp
+
+Use Lightpanda with [Chromedp](https://github.com/chromedp/chromedp), a Go client for the [Chrome DevTools Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP).
+
+
+
+Start Lightpanda as a local CDP server (see [serve command](/run-locally/commands/serve) for all options):
+
+```sh copy
+./lightpanda serve --host 127.0.0.1 --port 9222
+```
+
+Connect Chromedp using `NewRemoteAllocator`:
+
+```go copy
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ "github.com/chromedp/chromedp"
+)
+
+func main() {
+ ctx, cancel = chromedp.NewRemoteAllocator(ctx,
+ "ws://127.0.0.1:9222", chromedp.NoModifyURL,
+ )
+ defer cancel()
+
+ ctx, cancel := chromedp.NewContext(allocatorContext)
+ defer cancel()
+
+ var title string
+ if err := chromedp.Run(ctx,
+ chromedp.Navigate("https://wikipedia.com/"),
+ chromedp.Title(&title),
+ ); err != nil {
+ log.Fatalf("Failed getting page's title: %v", err)
+ }
+
+ log.Println("Got title of:", title)
+}
+```
+
+
+Export your API token and connect to the cloud endpoint:
+
+```sh copy
+export LPD_TOKEN="your token here"
+```
+
+```go copy
+package main
+
+import (
+ "context"
+ "log"
+ "os"
+
+ "github.com/chromedp/chromedp"
+)
+
+func main() {
+ ctx, cancel := chromedp.NewRemoteAllocator(context.Background(),
+ "wss://euwest.cloud.lightpanda.io/ws?token="+os.Getenv("LPD_TOKEN"), chromedp.NoModifyURL,
+ )
+ defer cancel()
+
+ ctx, cancel = chromedp.NewContext(ctx)
+ defer cancel()
+
+ var title string
+ if err := chromedp.Run(ctx,
+ chromedp.Navigate("https://lightpanda.io"),
+ chromedp.Title(&title),
+ ); err != nil {
+ log.Fatalf("Failed getting title of lightpanda.io: %v", err)
+ }
+
+ log.Println("Got title of:", title)
+}
+```
+
+More examples in [demo/chromedp](https://github.com/lightpanda-io/demo/tree/main/chromedp).
+
+## Cloud options
+
+Depending on your location, connect using:
+- `wss://euwest.cloud.lightpanda.io/ws` (west Europe)
+- `wss://uswest.cloud.lightpanda.io/ws` (west US)
+
+### Browser
+
+By default the cloud serves [Lightpanda browsers](https://github.com/lightpanda-io/browser).
+Use `browser=chrome` to select Google Chrome, or `browser=lightpanda` to force Lightpanda.
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?browser=chrome&token=TOKEN
+```
+
+### Proxies
+
+**fast_dc** — default, a single shared datacenter IP.
+
+**datacenter** — a pool of shared datacenter IPs with automatic rotation. Accepts an optional `country` query parameter (two-letter country code).
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?proxy=datacenter&country=de&token=TOKEN
+```
+
+[Contact us](mailto:hello@lightpanda.io) for additional proxy options.
+
+
diff --git a/src/content/usage/cdp/playwright.mdx b/src/content/usage/cdp/playwright.mdx
new file mode 100644
index 0000000..3b7384a
--- /dev/null
+++ b/src/content/usage/cdp/playwright.mdx
@@ -0,0 +1,91 @@
+---
+title: Playwright
+description: Use Lightpanda with Playwright via CDP, locally or on the cloud.
+---
+import { Tabs } from 'nextra/components'
+
+# Playwright
+
+Use Lightpanda with [Playwright](https://playwright.dev/) via the [Chrome DevTools Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP).
+
+
+
+Start Lightpanda as a local CDP server (see [serve command](/run-locally/commands/serve) for all options):
+
+```sh copy
+./lightpanda serve --host 127.0.0.1 --port 9222
+```
+
+Connect Playwright using `chromium.connectOverCDP`:
+
+```js copy
+import { chromium } from 'playwright-core';
+
+const browser = await chromium.connectOverCDP('ws://127.0.0.1:9222');
+
+const context = await browser.newContext({});
+const page = await context.newPage();
+
+await page.goto('https://wikipedia.com/');
+
+const title = await page.locator('h1').textContent();
+console.log(title);
+
+await page.close();
+await context.close();
+await browser.close();
+```
+
+
+Export your API token and connect to the cloud endpoint:
+
+```sh copy
+export LPD_TOKEN="your token here"
+```
+
+```js copy
+import playwright from "playwright-core";
+
+const browser = await playwright.chromium.connectOverCDP(
+ "wss://euwest.cloud.lightpanda.io/ws?token=" + process.env.LPD_TOKEN,
+);
+const context = await browser.newContext();
+const page = await context.newPage();
+
+// ...
+
+await page.close();
+await context.close();
+await browser.close();
+```
+
+More examples in [demo/playwright](https://github.com/lightpanda-io/demo/tree/main/playwright).
+
+## Cloud options
+
+Depending on your location, connect using:
+- `wss://euwest.cloud.lightpanda.io/ws` (west Europe)
+- `wss://uswest.cloud.lightpanda.io/ws` (west US)
+
+### Browser
+
+By default the cloud serves [Lightpanda browsers](https://github.com/lightpanda-io/browser).
+Use `browser=chrome` to select Google Chrome, or `browser=lightpanda` to force Lightpanda.
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?browser=chrome&token=TOKEN
+```
+
+### Proxies
+
+**fast_dc** — default, a single shared datacenter IP.
+
+**datacenter** — a pool of shared datacenter IPs with automatic rotation. Accepts an optional `country` query parameter (two-letter country code).
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?proxy=datacenter&country=de&token=TOKEN
+```
+
+[Contact us](mailto:hello@lightpanda.io) for additional proxy options.
+
+
diff --git a/src/content/usage/cdp/puppeteer.mdx b/src/content/usage/cdp/puppeteer.mdx
new file mode 100644
index 0000000..30886fb
--- /dev/null
+++ b/src/content/usage/cdp/puppeteer.mdx
@@ -0,0 +1,100 @@
+---
+title: Puppeteer
+description: Use Lightpanda with Puppeteer via CDP, locally or on the cloud.
+---
+import { Tabs } from 'nextra/components'
+
+# Puppeteer
+
+Use Lightpanda with [Puppeteer](https://pptr.dev/) via the [Chrome DevTools Protocol](https://chromedevtools.github.io/devtools-protocol/) (CDP).
+
+
+
+Start Lightpanda as a local CDP server (see [serve command](/run-locally/commands/serve) for all options):
+
+```sh copy
+./lightpanda serve --host 127.0.0.1 --port 9222
+```
+
+Connect Puppeteer using `browserWSEndpoint`:
+
+```js copy
+'use strict'
+
+import puppeteer from 'puppeteer-core'
+
+const browser = await puppeteer.connect({
+ browserWSEndpoint: "ws://127.0.0.1:9222",
+})
+
+const context = await browser.createBrowserContext()
+const page = await context.newPage()
+
+await page.goto('https://wikipedia.com/')
+
+const links = await page.evaluate(() => {
+ return Array.from(document.querySelectorAll('a')).map(row => {
+ return row.getAttribute('href')
+ })
+})
+
+console.log(links)
+
+await page.close()
+await context.close()
+await browser.disconnect()
+```
+
+
+Export your API token and connect to the cloud endpoint:
+
+```sh copy
+export LPD_TOKEN="your token here"
+```
+
+```js copy
+import puppeteer from 'puppeteer-core';
+
+const browser = await puppeteer.connect({
+ browserWSEndpoint: "wss://euwest.cloud.lightpanda.io/ws?token=" + process.env.LPD_TOKEN,
+});
+const context = await browser.createBrowserContext();
+const page = await context.newPage();
+
+// ...
+
+await page.close();
+await context.close();
+await browser.disconnect();
+```
+
+More examples in [demo/puppeteer](https://github.com/lightpanda-io/demo/tree/main/puppeteer).
+
+## Cloud options
+
+Depending on your location, connect using:
+- `wss://euwest.cloud.lightpanda.io/ws` (west Europe)
+- `wss://uswest.cloud.lightpanda.io/ws` (west US)
+
+### Browser
+
+By default the cloud serves [Lightpanda browsers](https://github.com/lightpanda-io/browser).
+Use `browser=chrome` to select Google Chrome, or `browser=lightpanda` to force Lightpanda.
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?browser=chrome&token=TOKEN
+```
+
+### Proxies
+
+**fast_dc** — default, a single shared datacenter IP.
+
+**datacenter** — a pool of shared datacenter IPs with automatic rotation. Accepts an optional `country` query parameter (two-letter country code).
+
+```text copy
+wss://euwest.cloud.lightpanda.io/ws?proxy=datacenter&country=de&token=TOKEN
+```
+
+[Contact us](mailto:hello@lightpanda.io) for additional proxy options.
+
+
diff --git a/src/content/open-source/guides/mcp-server.mdx b/src/content/usage/mcp.mdx
similarity index 56%
rename from src/content/open-source/guides/mcp-server.mdx
rename to src/content/usage/mcp.mdx
index 7a453e5..c281919 100644
--- a/src/content/open-source/guides/mcp-server.mdx
+++ b/src/content/usage/mcp.mdx
@@ -1,19 +1,22 @@
---
-title: Native MCP server
-description: Lightpanda ships a native Model Context Protocol server built into the browser binary. One binary, one command, full browser capabilities for your AI agent.
+title: MCP
+description: Use Lightpanda via the Model Context Protocol, locally or on the cloud.
---
+import { Tabs } from 'nextra/components'
-# Use Native MCP server
+# MCP
-Lightpanda v0.2.5 ships a **native Model Context Protocol (MCP) server** built directly into the browser binary. The MCP server shares the same process as the Zig-based JavaScript engine with no CDP intermediary and no extra processes.
+Use Lightpanda via the [Model Context Protocol](https://modelcontextprotocol.io) (MCP) to control the browser from AI applications.
+
+
+
+Start the MCP server over stdio:
```sh copy
-lightpanda mcp
+./lightpanda mcp
```
-The server communicates via **MCP JSON-RPC 2.0 over stdio**, making it compatible with Claude Desktop, Cursor, Windsurf, and any MCP-aware agent framework.
-
-## Tools and resources
+### Tools
| Name | Description |
|-|-|
@@ -39,7 +42,7 @@ Navigate to a URL and load the page into memory.
"params":{"name":"goto","arguments":{"url":"https://example.com"}}}
```
-**Response:** `"Navigated successfully."` - returned even if the URL is unreachable. Always verify with a follow-up content call (see [Known behaviors](#known-behaviors)).
+**Response:** `"Navigated successfully."` — returned even if the URL is unreachable. Always verify with a follow-up content call (see [Known behaviors](#known-behaviors)).
#### `markdown`
@@ -59,7 +62,7 @@ Extract the current page's content as clean, token-efficient markdown.
-> Using `markdown` with an inline `url` is the most efficient single-call pattern - it navigates and extracts in one request. Essential for HTTP transport where sessions are stateless.
+> Using `markdown` with an inline `url` is the most efficient single-call pattern — it navigates and extracts in one request. Essential for HTTP transport where sessions are stateless.
#### `links`
@@ -106,9 +109,76 @@ Two read-only resources are available after a page has been loaded via `resource
> The `markdown` tool and the `mcp://page/markdown` resource return the same content. The difference is who initiates: **tools** are called by the agent during its workflow; **resources** are read by the host application (e.g. an IDE displaying page state in the background).
-## Connecting an AI agent
+### Options
+
+```bash
+--insecure-disable-tls-host-verification
+ Disables host verification on all HTTP requests. This is an
+ advanced option which should only be set if you understand
+ and accept the risk of disabling host verification.
+
+--obey-robots
+ Fetches and obeys the robots.txt (if available) of the web pages
+ we make requests towards.
+ Defaults to false.
+
+--http-proxy The HTTP proxy to use for all HTTP requests.
+ A username:password can be included for basic authentication.
+ Defaults to none.
+
+--proxy-bearer-token
+ The to send for bearer authentication with the proxy
+ Proxy-Authorization: Bearer
+
+--http-max-concurrent
+ The maximum number of concurrent HTTP requests.
+ Defaults to 10.
+
+--http-max-host-open
+ The maximum number of open connection to a given host:port.
+ Defaults to 4.
+
+--http-connect-timeout
+ The time, in milliseconds, for establishing an HTTP connection
+ before timing out. 0 means it never times out.
+ Defaults to 0.
+
+--http-timeout
+ The maximum time, in milliseconds, the transfer is allowed
+ to complete. 0 means it never times out.
+ Defaults to 10000.
+
+--http-max-response-size
+ Limits the acceptable response size for any request
+ (e.g. XHR, fetch, script loading, ...).
+ Defaults to no limit.
+
+--log-level The log level: debug, info, warn, error or fatal.
+ Defaults towarn.
+
+--log-format The log format: pretty or logfmt.
+ Defaults to logfmt.
+
+--log-filter-scopes
+ Filter out too verbose logs per scope:
+ http, unknown_prop, event, ...
+
+--user-agent-suffix
+ Suffix to append to the Lightpanda/X.Y User-Agent
+
+--web-bot-auth-key-file
+ Path to the Ed25519 private key PEM file.
-### Claude Desktop / Cursor / Windsurf
+--web-bot-auth-keyid
+ The JWK thumbprint of your public key.
+
+--web-bot-auth-domain
+ Your domain e.g. yourdomain.com
+```
+
+### Connecting an AI agent
+
+#### Claude Desktop / Cursor / Windsurf
Add to your MCP host configuration:
@@ -116,7 +186,7 @@ Add to your MCP host configuration:
- **Cursor:** `.cursor/mcp.json` in your project
- **Windsurf:** Cascade MCP settings
-```json
+```json copy
{
"mcpServers": {
"lightpanda": {
@@ -127,11 +197,11 @@ Add to your MCP host configuration:
}
```
-For robots.txt compliance, use `"args": ["mcp", "--obey_robots"]`.
+For robots.txt compliance, use `"args": ["mcp", "--obey-robots"]`.
> Replace `/path/to/lightpanda` with the actual binary path, e.g. `/usr/local/bin/lightpanda`.
-### HTTP transport via supergateway
+#### HTTP transport via supergateway
Lightpanda MCP natively supports only stdio. To expose it over HTTP, use [supergateway](https://www.npmjs.com/package/supergateway) as a bridge.
@@ -143,11 +213,11 @@ npx -y supergateway \
--port 8000
```
-> By default, supergateway is **stateless**: each HTTP request spawns a fresh process. For stateful sessions, we use `--stateful --sessionTimeout ` to the supergateway command.
+> By default, supergateway is **stateless**: each HTTP request spawns a fresh process. Use `--stateful --sessionTimeout ` for stateful sessions.
With robots.txt: `--stdio "lightpanda mcp --obey-robots"`
-#### Calling the HTTP endpoint
+##### Calling the HTTP endpoint
```sh copy
# Initialize
@@ -166,9 +236,9 @@ curl -X POST http://localhost:8000/mcp \
"params":{"name":"markdown","arguments":{"url":"https://example.com"}}}'
```
-## Known behaviors
+### Known behaviors
-### `goto` always returns success
+#### `goto` always returns success
`goto` returns `"Navigated successfully."` even for invalid or unreachable URLs. The failure surfaces on the next content call:
@@ -180,24 +250,56 @@ Reason: CouldntResolveHost
Always check the content result after navigation, not the `goto` response itself.
-### Debugging
+#### Debugging
Lightpanda defaults to `--log-level warn`. Setting `info` surfaces HTTP requests, navigation events, resource loading, and robots.txt fetches. All logs go to **stderr** and never interfere with stdout.
```sh copy
-lightpanda mcp --log_level info --log_format pretty
+lightpanda mcp --log-level info --log-format pretty
# Or pipe logs to a file
-lightpanda mcp --log_level info 2>lightpanda.log
+lightpanda mcp --log-level info 2>lightpanda.log
```
-Use `--log_level debug` for the most verbose output. Keep `warn` in production.
+Use `--log-level debug` for the most verbose output. Keep `warn` in production.
-## References
+### References
-- [LP Domain & Native MCP - Lightpanda Blog](https://lightpanda.io/blog/posts/lp-domain-commands-and-native-mcp)
+- [LP Domain & Native MCP — Lightpanda Blog](https://lightpanda.io/blog/posts/lp-domain-commands-and-native-mcp)
- [Lightpanda GitHub](https://github.com/lightpanda-io/browser)
- [Lightpanda releases](https://github.com/lightpanda-io/browser/releases)
- [MCP Specification](https://modelcontextprotocol.io/)
- [supergateway (npm)](https://www.npmjs.com/package/supergateway)
-- [Lightpanda Cloud MCP (SSE)](https://lightpanda.io/docs/cloud-offer/tools/mcp)
+
+
+The Lightpanda cloud MCP service supports [SSE](https://modelcontextprotocol.io/specification/2024-11-05/basic/transports#http-with-sse) transport.
+
+Depending on your location, connect using:
+- `https://euwest.cloud.lightpanda.io/mcp/sse` (west Europe)
+- `https://uswest.cloud.lightpanda.io/mcp/sse` (west US)
+
+### Authentication
+
+Pass your token as a query string parameter or via `Authorization: Bearer` HTTP header.
+
+```text copy
+https://euwest.cloud.lightpanda.io/mcp/sse?token=TOKEN
+```
+
+```text copy
+https://euwest.cloud.lightpanda.io/mcp/sse
+Authorization: Bearer TOKEN
+```
+
+### Tools
+
+| Name | Description |
+|-|-|
+| search | Search a term on a web search engine and get the search results. |
+| goto | Navigate to a specified URL and load the page in memory so it can be reused later for info extraction. |
+| markdown | Get the page in memory content in markdown format. Run a goto before getting markdown. |
+| links | Extract all links from the page in memory. Run a goto before getting links. |
+
+For more advanced use cases, use [CDP with Playwright MCP](https://github.com/microsoft/playwright-mcp).
+
+